Advanced Structured Prediction
Nowozin, S.,
Gehler, P.V., Jancsary, J. and Lampert, C.H.
Advanced Structured Prediction.
Neural Information Processing Series,
MIT Press,
2014.
Abstract:
▸
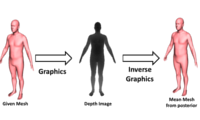
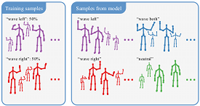
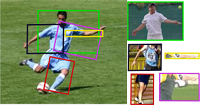
The goal of structured prediction is to build machine learning models that predict relational information that itself has structure, such as being composed of multiple interrelated parts. These models, which reflect prior knowledge, task-specific relations, and constraints, are used in fields including computer vision, speech recognition, natural language processing, and computational biology. They can carry out such tasks as predicting a natural language sentence, or segmenting an image into meaningful components.
These models are expressive and powerful, but exact computation is often intractable. A broad research effort in recent years has aimed at designing structured prediction models and approximate inference and learning procedures that are computationally efficient. This volume offers an overview of this recent research in order to make the work accessible to a broader research community. The chapters, by leading researchers in the field, cover a range of topics, including research trends, the linear programming relaxation approach, innovations in probabilistic modeling, recent theoretical progress, and resource-aware learning.
Sending email...