
Export search results as: BibTex
2015






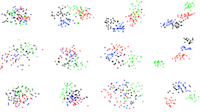









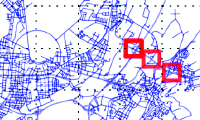


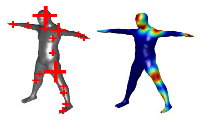

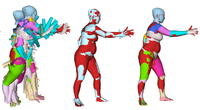
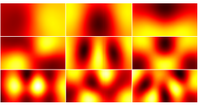






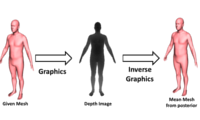
The Informed Sampler: A Discriminative Approach to Bayesian Inference in Generative Computer Vision Models
In
Special Issue on Generative Models in Computer Vision and Medical Imaging,
Computer Vision and Image Understanding, Elsevier,
Vol. 136,
pages 32-44,
July
2015.
Abstract:
▸
[arXiv]
[BibTex]
[Share]
2014















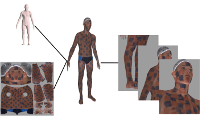
Automated Detection of New or Evolving Melanocytic Lesions Using a 3D Body Model
In
Medical Image Computing and Computer-Assisted Intervention (MICCAI),
Spring International Publishing,
Vol. 8673,
Lecture Notes in Computer Science,
pages 593-600,
September
2014.
Abstract:
▸
[pdf]
[Poster]
[BibTex]
[Share]



