Export search results as:
BibTex
2014

Omnidirectional 3D Reconstruction in Augmented Manhattan Worlds
International Conference on Intelligent Robots and Systems,
IEEE,
Chicago, IL, USA.
pages 716 - 723,
October
2014.
Abstract:
▸
This paper proposes a method for high-quality omnidirectional 3D reconstruction of augmented Manhattan worlds from catadioptric stereo video sequences. In contrast to existing works we do not rely on constructing virtual perspective views, but instead propose to optimize depth jointly in a unified omnidirectional space. Furthermore, we show that plane-based prior models can be applied even though planes in 3D do not project to planes in the omnidirectional domain. Towards this goal, we propose an omnidirectional slanted-plane Markov random field model which relies on plane hypotheses extracted using a novel voting scheme for 3D planes in omnidirectional space. To quantitatively evaluate our method we introduce a dataset which we have captured using our autonomous driving platform AnnieWAY which we equipped with two horizontally aligned catadioptric cameras and a Velodyne HDL-64E laser scanner for precise ground truth depth measurements. As evidenced by our experiments, the proposed method clearly benefits from the unified view and significantly outperforms existing stereo matching techniques both quantitatively and qualitatively. Furthermore, our method is able to reduce noise and the obtained depth maps can be represented very compactly by a small number of image segments and plane parameters.
[Share]
Sending email...

Hough-based Object Detection with Grouped Features
International Conference on Image Processing,
Paris, France.
pages 1653-1657,
October
2014.
Abstract:
▸
Hough-based voting approaches have been successfully applied to object detection. While these methods can be efficiently implemented by random forests, they estimate the probability for an object hypothesis for each feature independently. In this work, we address this problem by grouping features in a local neighborhood to obtain a better estimate of the probability. To this end, we propose oblique classification-regression forests that combine features of different trees. We further investigate the benefit of combining independent and grouped features and evaluate the approach on RGB and RGB-D datasets.
[Share]
Sending email...

Preserving Modes and Messages via Diverse Particle Selection
Pacheco, J.,
Zuffi, S.,
Black, M.J. and Sudderth, E.
In
Proceedings of the 31st International Conference on Machine Learning (ICML-14),
J. Machine Learning Research Workshop and Conf. and Proc.,
Vol. 32,
pages 1152-1160,
Beijing, China.
June
2014.
Abstract:
▸
In applications of graphical models arising in domains such as computer vision and signal processing,
we often seek the most likely configurations of high-dimensional, continuous variables. We develop a particle-based max-product algorithm which maintains a diverse set of posterior mode hypotheses, and is robust to initialization.
At each iteration, the set of hypotheses at each node is augmented via stochastic proposals, and then reduced via an efficient selection algorithm. The integer program underlying our optimization-based particle selection minimizes
errors in subsequent max-product message updates. This objective automatically encourages diversity in the maintained hypotheses, without requiring tuning of application-specific distances among hypotheses. By avoiding the stochastic resampling steps underlying particle sum-product algorithms, we also avoid common degeneracies where particles collapse onto a single hypothesis. Our approach significantly outperforms previous particle-based algorithms in experiments focusing on the estimation of human pose from single images.
[Share]
Sending email...

Breathing Life into Shape: Capturing, Modeling and Animating 3D Human Breathing
ACM Transactions on Graphics, (Proc. SIGGRAPH),
33(4):52:1-52:11,
July
2014.
Abstract:
▸
Modeling how the human body deforms during breathing is important for the realistic animation of lifelike 3D avatars. We learn a model of body shape deformations due to breathing for different breathing types and provide simple animation controls to render lifelike breathing regardless of body shape. We capture and align high-resolution 3D scans of 58 human subjects. We compute deviations from each subject’s mean shape during breathing, and study the statistics of such shape changes for different genders, body shapes, and breathing types. We use the volume of the registered scans as a proxy for lung volume and learn a novel non-linear model relating volume and breathing type to 3D shape deformations and pose changes. We then augment a SCAPE body model so that body shape is determined by identity, pose, and the parameters of the breathing model. These parameters provide an intuitive interface with which animators can synthesize 3D human avatars with realistic breathing motions. We also develop a novel interface for animating breathing using a spirometer, which measures the changes in breathing volume of a “breath actor.”
[Share]
Sending email...
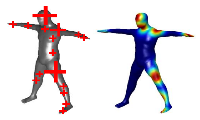
Posebits for Monocular Human Pose Estimation
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
pages 2345-2352,
Columbus, Ohio, USA.
June
2014.
Abstract:
▸
We advocate the inference of qualitative information about 3D human
pose, called posebits, from images. Posebits represent boolean
geometric relationships between body parts
(e.g., left-leg in front of right-leg or hands close to each other).
The advantages of posebits as a mid-level representation are 1)
for many tasks of interest, such qualitative
pose information may be sufficient (e.g. \, semantic image retrieval),
2) it is relatively easy to annotate large image corpora with posebits, as
it simply requires answers to yes/no questions; and 3) they help
resolve challenging pose ambiguities and therefore
facilitate the difficult talk of image-based 3D pose estimation.
We introduce posebits, a posebit database, a method for selecting useful
posebits for pose estimation and a structural SVM model for posebit inference.
Experiments show the use of posebits for semantic image
retrieval and for improving 3D pose estimation.
[Share]
Sending email...
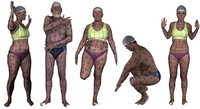
FAUST: Dataset and evaluation for 3D mesh registration
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
pages 3794 -3801,
Columbus, Ohio, USA.
June
2014.
Abstract:
▸
New scanning technologies are increasing the importance of 3D mesh data and the need for algorithms that can reliably align it. Surface registration is important for building full 3D models from partial scans, creating statistical shape models, shape retrieval, and tracking. The problem is particularly challenging for non-rigid and articulated objects like human bodies. While the challenges of real-world data registration are not present in existing synthetic datasets, establishing ground-truth correspondences for real 3D scans is difficult. We address this with a novel mesh registration technique that combines 3D shape and appearance information to produce high-quality alignments. We define a new dataset called FAUST that contains 300 scans of 10 people in a wide range of poses together with an evaluation methodology. To achieve accurate registration, we paint the subjects with high-frequency textures
and use an extensive validation process to ensure accurate ground truth. We find that current shape registration methods have trouble with this real-world data. The dataset and evaluation website are available for research purposes at http://faust.is.tue.mpg.de.
[Share]
Sending email...

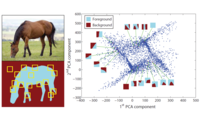
Grassmann Averages for Scalable Robust PCA
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
pages 3810 -3817,
Columbus, Ohio, USA.
June
2014.
Abstract:
▸
As the collection of large datasets becomes increasingly automated, the occurrence of outliers will increase – “big
data” implies “big outliers”. While principal component analysis (PCA) is often used to reduce the size of data, and
scalable solutions exist, it is well-known that outliers can arbitrarily corrupt the results. Unfortunately, state-of-the-art approaches for robust PCA do not scale beyond small-to-medium sized datasets. To address this, we introduce the Grassmann Average (GA), which expresses dimensionality reduction as an average of the subspaces spanned by the data. Because averages can be efficiently computed, we immediately gain scalability. GA is inherently more robust than PCA, but we show that they coincide for Gaussian data. We exploit that averages can be made robust to formulate the Robust Grassmann Average (RGA) as a form of robust PCA. Robustness can be with respect to vectors (subspaces) or elements of vectors; we focus on the latter and use a trimmed average. The resulting Trimmed Grassmann Average (TGA) is particularly appropriate for computer vision because it is robust to pixel outliers. The algorithm has low computational complexity and minimal memory requirements, making it scalable to “big noisy data.” We demonstrate TGA for background modeling, video restoration, and shadow removal. We show scalability by performing robust PCA on the entire Star Wars IV movie.
[Share]
Sending email...
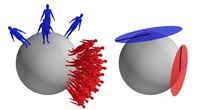
Model Transport: Towards Scalable Transfer Learning on Manifolds
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
pages 1378 -1385,
Columbus, Ohio, USA.
June
2014.
Abstract:
▸
We consider the intersection of two research fields: transfer learning and statistics on manifolds. In particular, we consider, for manifold-valued data, transfer learning of tangent-space models such as Gaussians distributions,
PCA, regression, or classifiers. Though one would hope to simply use ordinary Rn-transfer learning ideas, the manifold structure prevents it. We overcome this by basing our method on inner-product-preserving parallel transport, a well-known tool widely used in other problems of statistics on manifolds in computer vision. At first, this straightforward idea seems to suffer from an obvious shortcoming: Transporting large datasets is prohibitively expensive, hindering scalability. Fortunately, with our approach, we never transport data. Rather, we show how the statistical models themselves can be transported, and prove that for the tangent-space models above, the transport “commutes” with learning. Consequently, our compact framework, applicable to a large class of manifolds, is not restricted by the size of either the training or test sets. We demonstrate the approach by transferring PCA and logistic-regression models of real-world data involving 3D shapes and image descriptors.
[Share]
Sending email...

Multi-View Priors for Learning Detectors from Sparse Viewpoint Data
Pepik, B., Stark, M.,
Gehler, P. and Schiele, B.
International Conference on Learning Representations,
2014.
Abstract:
▸
While the majority of today's object class models provide only 2D bounding boxes, far richer output hypotheses are desirable including viewpoint, fine-grained category, and 3D geometry estimate. However, models trained to provide richer output require larger amounts of training data, preferably well covering the relevant aspects such as viewpoint and fine-grained categories. In this paper, we address this issue from the perspective of transfer learning, and design an object class model that explicitly leverages correlations between visual features. Specifically, our model represents prior distributions over permissible multi-view detectors in a parametric way -- the priors are learned once from training data of a source object class, and can later be used to facilitate the learning of a detector for a target class. As we show in our experiments, this transfer is not only beneficial for detectors based on basic-level category representations, but also enables the robust learning of detectors that represent classes at finer levels of granularity, where training data is typically even scarcer and more unbalanced. As a result, we report largely improved performance in simultaneous 2D object localization and viewpoint estimation on a recent dataset of challenging street scenes.
[Share]
Sending email...
Human Pose Estimation: New Benchmark and State of the Art Analysis
Andriluka, M., Pishchulin, L.,
Gehler, P. and Schiele, B.
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
IEEE,
June
2014.
[Share]
Sending email...

Calibrating and Centering Quasi-Central Catadioptric Cameras
Schoenbein, M., Strauss, T. and
Geiger, A.
IEEE International Conference on Robotics and Automation,
Hong Kong, China.
pages 4443 - 4450,
June
2014.
Abstract:
▸
Non-central catadioptric models are able to cope with irregular camera setups and inaccuracies in the manufacturing process but are computationally demanding and thus not suitable for robotic applications. On the other hand, calibrating a quasi-central (almost central) system with a central model introduces errors due to a wrong relationship between the viewing ray orientations and the pixels on the image sensor. In this paper, we propose a central approximation to quasi-central catadioptric camera systems that is both accurate and efficient. We observe that the distance to points in 3D is typically large compared to deviations from the single viewpoint. Thus, we first calibrate the system using a state-of-the-art non-central camera model. Next, we show that by remapping the observations we are able to match the orientation of the viewing rays of a much simpler single viewpoint model with the true ray orientations. While our approximation is general and applicable to all quasi-central camera systems, we focus on one of the most common cases in practice: hypercatadioptric cameras. We compare our model to a variety of baselines in synthetic and real localization and motion estimation experiments. We show that by using the proposed model we are able to achieve near non-central accuracy while obtaining speed-ups of more than three orders of magnitude compared to state-of-the-art non-central models.
[Share]
Sending email...

Simultaneous Underwater Visibility Assessment, Enhancement and Improved Stereo
Roser, M., Dunbabin, M. and
Geiger, A.
IEEE International Conference on Robotics and Automation,
Hong Kong, China.
pages 3840 - 3847 ,
June
2014.
Abstract:
▸
Vision-based underwater navigation and obstacle avoidance demands robust computer vision algorithms, particularly for operation in turbid water with reduced visibility. This paper describes a novel method for the simultaneous underwater image quality assessment, visibility enhancement and disparity computation to increase stereo range resolution under dynamic, natural lighting and turbid conditions. The technique estimates the visibility properties from a sparse 3D map of the original degraded image using a physical underwater light attenuation model. Firstly, an iterated distance-adaptive image contrast enhancement enables a dense disparity computation and visibility estimation. Secondly, using a light attenuation model for ocean water, a color corrected stereo underwater image is obtained along with a visibility distance estimate. Experimental results in shallow, naturally lit, high-turbidity coastal environments show the proposed technique improves range estimation over the original images as well as image quality and color for habitat classification. Furthermore, the recursiveness and robustness of the technique allows real-time implementation onboard an Autonomous Underwater Vehicles for improved navigation and obstacle avoidance performance.
[Share]
Sending email...

NRSfM using Local Rigidity
Rehan, A., Zaheer, A.,
Akhter, I., Saeed, A., Mahmood, B., Usmani, M. and Khan, S.
In
Proceedings Winter Conference on Applications of Computer Vision,
IEEE ,
pages 69-74,
Steamboat Springs, CO, USA.
March
2014.
Abstract:
▸
Factorization methods for computation of nonrigid structure have limited practicality, and work well only when there is large enough camera motion between frames, with long sequences and limited or no occlusions. We show that typical nonrigid structure can often be approximated well as locally rigid sub-structures in time and space. Specifically, we assume that: 1) the structure can be approximated as rigid in a short local time window and 2) some point pairs stay relatively rigid in space, maintaining a fixed distance between them during the sequence. We first use the triangulation constraints in rigid SFM over a sliding time window to get an initial estimate of the nonrigid 3D structure. We then automatically identify relatively rigid point pairs in this structure, and use their length-constancy simultaneously with triangulation constraints to refine the structure estimate. Unlike factorization methods, the structure is estimated independent of the camera motion computation, adding to the simplicity and stability of the approach. Further,
local factorization inherently handles significant natural occlusions gracefully, performing much better than the state-of-the art. We show more stable and accurate results as compared to the state-of-the art on even short sequences starting from 15 frames only, containing camera rotations
as small as 2 degree� and up to 50% missing data.
[Share]
Sending email...
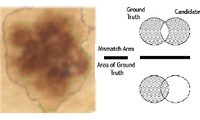
Simpler, faster, more accurate melanocytic lesion segmentation through MEDS
Peruch, F.,
Bogo, F., Bonazza, M., Cappelleri, V. and Peserico, E.
IEEE Transactions on Biomedical Engineering,
61(2):557-565,
February
2014.
[Share]
Sending email...
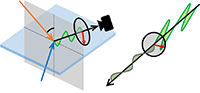
A physically-based approach to reflection separation: from physical modeling to constrained optimization
Kong, N., Tai, Y. and Shin, J.S.
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI),
36(2):209-221,
February
2014.
Abstract:
▸
We propose a physically-based approach to separate reflection using multiple polarized images with a background scene captured behind glass. The input consists of three polarized images, each captured from the same view point but with a different polarizer angle separated by 45 degrees. The output is the high-quality separation of the reflection and background layers from each of the input images. A main technical challenge for this problem is that the mixing coefficient for the reflection and background layers depends on the angle of incidence and the orientation of the plane of incidence, which are spatially varying over the pixels of an image. Exploiting physical properties of polarization for a double-surfaced glass medium, we propose a multiscale scheme which automatically finds the optimal separation of the reflection and background layers. Through experiments, we demonstrate that our approach can generate superior results to those of previous methods.
[Share]
Sending email...

Efficient Non-linear Markov Models for Human Motion
In
Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 1314-1321,
June
2014.
Abstract:
▸
Dynamic Bayesian networks such as Hidden Markov
Models (HMMs) are successfully used as probabilistic models
for human motion. The use of hidden variables makes
them expressive models, but inference is only approximate
and requires procedures such as particle filters or Markov
chain Monte Carlo methods. In this work we propose to instead
use simple Markov models that only model observed
quantities. We retain a highly expressive dynamic model by
using interactions that are nonlinear and non-parametric.
A presentation of our approach in terms of latent variables
shows logarithmic growth for the computation of exact loglikelihoods
in the number of latent states. We validate
our model on human motion capture data and demonstrate
state-of-the-art performance on action recognition and motion
completion tasks.
[Share]
Sending email...

Probabilistic Solutions to Differential Equations and their Application to Riemannian Statistics
In
Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics,
Microtome Publishing,
Vol. 33,
JMLR: Workshop and Conference Proceedings,
pages 347-355,
Brookline, MA.
April
2014.
Abstract:
▸
We study a probabilistic numerical method for the solution of both
boundary and initial value problems that returns a joint Gaussian
process posterior over the solution. Such methods have concrete value
in the statistics on Riemannian manifolds, where non-analytic ordinary
differential equations are involved in virtually all computations. The
probabilistic formulation permits marginalising the uncertainty of the
numerical solution such that statistics are less sensitive to
inaccuracies. This leads to new Riemannian algorithms for mean value
computations and principal geodesic analysis. Marginalisation also
means results can be less precise than point estimates, enabling a
noticeable speed-up over the state of the art. Our approach is an
argument for a wider point that uncertainty caused by numerical
calculations should be tracked throughout the pipeline of machine
learning algorithms.
[Share]
Sending email...

Model-based Anthropometry: Predicting Measurements from 3D Human Scans in Multiple Poses
In
Proceedings Winter Conference on Applications of Computer Vision,
IEEE ,
pages 83-90,
March
2014.
Abstract:
▸
Extracting anthropometric or tailoring measurements from 3D human body scans is important for applications such as virtual try-on, custom clothing, and online sizing. Existing commercial solutions identify anatomical landmarks on high-resolution 3D scans and then compute distances or circumferences on the scan. Landmark detection is sensitive to acquisition noise (e.g. holes) and these methods require subjects to adopt a specific pose. In contrast, we propose a solution we call model-based anthropometry. We fit a deformable 3D body model to scan data in one or more poses; this model-based fitting is robust to scan noise. This brings the scan into registration with a database of registered body scans. Then, we extract features from the registered model (rather than from the scan); these include, limb lengths, circumferences, and statistical features of global shape. Finally, we learn a mapping from these features to measurements using regularized linear regression. We perform an extensive evaluation using the CAESAR dataset and demonstrate that the accuracy of our method outperforms state-of-the-art methods.
[Share]
Sending email...

Adaptive Offset Correction for Intracortical Brain Computer Interfaces
Homer, M.L., Perge, J.A.,
Black, M.J., Harrison, M.T., Cash, S.S. and Hochberg, L.R.
IEEE Transactions on Neural Systems and Rehabilitation Engineering,
22(2):239-248,
March
2014.
Abstract:
▸
Intracortical brain computer interfaces (iBCIs) decode intended movement from neural activity for the control of external devices such as a robotic arm. Standard approaches include a calibration phase to estimate decoding parameters. During iBCI operation, the statistical properties of the neural activity can depart from those observed during calibration, sometimes hindering a user’s ability to control the iBCI. To address this problem, we adaptively correct the offset terms within a Kalman filter decoder via penalized maximum likelihood estimation. The approach can handle rapid shifts in neural signal behavior (on the order of seconds) and requires no knowledge of the intended movement. The algorithm, called MOCA, was tested using simulated neural activity and evaluated retrospectively using data collected from two people with tetraplegia operating an iBCI. In 19 clinical research test cases, where a nonadaptive Kalman filter yielded relatively high decoding errors, MOCA significantly reduced these errors (10.6 ± 10.1\%; p < 0.05, pairwise t-test). MOCA did not significantly change the error in the remaining 23 cases where a nonadaptive Kalman filter already performed well. These results suggest that MOCA provides more robust decoding than the standard Kalman filter for iBCIs.
[Share]
Sending email...

3D Traffic Scene Understanding from Movable Platforms
Geiger, A., Lauer, M., Wojek, C., Stiller, C. and Urtasun, R.
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI),
36(5):1012-1025,
2014.
Abstract:
▸
In this paper, we present a novel probabilistic generative model for multi-object traffic scene understanding from movable platforms which reasons jointly about the 3D scene layout as well as the location and orientation of objects in the scene. In particular, the scene topology, geometry and traffic activities are inferred from short video sequences.
Inspired by the impressive driving capabilities of humans, our model does not rely on GPS, lidar or map knowledge. Instead, it takes advantage of a diverse set of visual cues in the form of vehicle tracklets, vanishing points, semantic scene labels, scene flow and occupancy grids. For each of these cues we propose likelihood functions that are integrated into a probabilistic generative model. We learn all model parameters from training data using contrastive divergence. Experiments conducted on videos of 113 representative intersections show that our approach successfully infers the correct layout in a variety of very challenging scenarios. To evaluate the importance of each feature cue, experiments using different feature combinations are conducted. Furthermore, we show how by employing context derived from the proposed method we are able to improve over the state-of-the-art in terms of object detection and object orientation estimation in challenging and cluttered urban environments.
[Share]
Sending email...

A Quantitative Analysis of Current Practices in Optical Flow Estimation and the Principles behind Them
International Journal of Computer Vision (IJCV),
106(2):115-137,
2014.
Abstract:
▸
The accuracy of optical flow estimation algorithms has been improving steadily as evidenced by results on the Middlebury optical flow benchmark. The typical formulation, however, has changed little since the work of Horn and Schunck. We attempt to uncover what has made recent advances possible through a thorough analysis of how the objective function, the optimization method, and modern implementation practices influence accuracy. We discover that "classical'' flow formulations perform surprisingly well when combined with modern optimization and implementation techniques. One key implementation detail is the median filtering of intermediate flow fields during optimization. While this improves the robustness of classical methods it actually leads to higher energy solutions, meaning that these methods are not optimizing the original objective function. To understand the principles behind this phenomenon, we derive a new objective function that formalizes the median filtering heuristic. This objective function includes a non-local smoothness term that robustly integrates flow estimates over large spatial neighborhoods. By modifying this new term to include information about flow and image boundaries we develop a method that can better preserve motion details. To take advantage of the trend towards video in wide-screen format, we further introduce an asymmetric pyramid downsampling scheme that enables the estimation of longer range horizontal motions. The methods are evaluated on Middlebury, MPI Sintel, and KITTI datasets using the same parameter settings.
[Share]
Sending email...
Simulated Annealing
In
Encyclopedia of Computer Vision,
Ikeuchi, K., Editors,
Springer Verlag
pages 737-741,
2014.
[Share]
Sending email...
2013

Methods and Applications for Distance Based ANN Training
In
IEEE International Conference on Machine Learning and Applications (ICMLA),
December
2013.
Abstract:
▸
Feature learning has the aim to take away the hassle of hand-designing features for machine learning tasks. Since the feature design process is tedious and requires a lot of experience,
an automated solution is of great interest. However, an important problem in this field is that usually no objective values are available to fit a feature learning function to.
Artificial Neural Networks are a sufficiently flexible tool for function approximation to be able to avoid this problem. We show how the error function of an ANN can be modified such that it works solely with objective distances instead of objective values. We derive the adjusted rules for backpropagation through networks with arbitrary depths and include practical considera-
tions that must be taken into account to apply difference based learning successfully.
On all three benchmark datasets we use, linear SVMs trained on automatically learned ANN features outperform RBF kernel SVMs trained on the raw data. This can be achieved in a feature space with up to only a tenth of dimensions of the number of original data dimensions. We conclude our work with two experiments on distance based ANN training in two further fields: data visualization and outlier detection.
[Share]
Sending email...

Right Ventricle Segmentation by Temporal Information Constrained Gradient Vector Flow
Yang, X.,
Yeo, S.Y., Su, Y., Lim, C., Wan, M., Zhong, L. and Tan, R.S.
In
IEEE International Conference on Systems, Man, and Cybernetics,
2013.
Abstract:
▸
Evaluation of right ventricular (RV) structure and function is of importance in the management of most cardiac disorders. But the segmentation of RV has always been consid- ered challenging due to low contrast of the myocardium with surrounding and high shape variability of the RV. In this paper, we present a 2D + T active contour model for segmentation and tracking of RV endocardium on cardiac magnetic resonance (MR) images. To take into account the temporal information between adjacent frames, we propose to integrate the time-dependent constraints into the energy functional of the classical gradient vector flow (GVF). As a result, the prior motion knowledge of RV is introduced in the deformation process through the time-dependent constraints in the proposed GVF-T model. A weighting parameter is introduced to adjust the weight of the temporal information against the image data itself. The additional external edge forces retrieved from the temporal constraints may be useful for the RV segmentation, such that lead to a better segmentation performance. The effectiveness of the proposed approach is supported by experimental results on synthetic and cardiac MR images.
[Share]
Sending email...

Model Reconstruction of Patient-Specific Cardiac Mesh from Segmented Contour Lines
Lim, C.W., Su, Y.,
Yeo, S.Y., Ng, G.M., Nguyen, V.T., Zhong, L., Tan, R.S., Poh, K.K. and P. Chai
In
Asia Pacific Congress on Computational Mechanics,
2013.
Abstract:
▸
We propose an automatic algorithm for the reconstruction of a set of patient-specific dynamic cardiac mesh model with 1-to-1 mesh correspondence over the whole cardiac cycle. This work focus on both the reconstruction technique of the initial 3D model of the heart and also the consistent mapping of the vertex positions throughout all the 3D meshes. This process is technically more challenging due to the wide interval spacing between MRI images as compared to CT images, making overlapping blood vessels much harder to discern. We propose a tree-based connectivity data structure to perform a filtering process to eliminate weak connections between contours on adjacent slices. The reconstructed 3D model from the first time step is used as a base template model, and deformed to fit the segmented contours in the next time step. Our algorithm has been tested on an actual acquisition of cardiac MRI images over one cardiac cycle.
[Share]
Sending email...
Dynamic Probabilistic Volumetric Models
Ulusoy, A.O., Biris, O. and Mundy, J.L.
In
ICCV,
pages 505-512,
2013.
Abstract:
▸
This paper presents a probabilistic volumetric framework for image based modeling of general dynamic 3-d scenes. The framework is targeted towards high quality modeling of complex scenes evolving over thousands of frames. Extensive storage and computational resources are required in processing large scale space-time (4-d) data. Existing methods typically store separate 3-d models at each time step and do not address such limitations. A novel 4-d representation is proposed that adaptively subdivides in space and time to explain the appearance of 3-d dynamic surfaces. This representation is shown to achieve compression of 4-d data and provide efficient spatio-temporal processing. The advances of the proposed framework is demonstrated on standard datasets using free-viewpoint video and 3-d tracking applications.
[Share]
Sending email...
Quasi-Newton Methods: A New Direction
Journal of Machine Learning Research,
14(1):843-865,
March
2013.
Abstract:
▸
Four decades after their invention, quasi-Newton methods are still state of the art in unconstrained numerical optimization. Although not usually interpreted thus, these are learning algorithms that fit a local quadratic approximation to the objective function. We show that many, including the most popular, quasi-Newton methods can be interpreted as approximations of Bayesian linear regression under varying prior assumptions. This new notion elucidates some shortcomings of classical algorithms, and lights the way to a novel nonparametric quasi-Newton method, which is able to make more efficient use of available information at computational cost similar to its predecessors.
[Share]
Sending email...
Extracting Postural Synergies for Robotic Grasping
Romero, J., Feix, T., Ek, C.H., Kjellstrom, H. and Kragic, D.
Robotics, IEEE Transactions on,
29(6):1342-1352,
December
2013.
[Share]
Sending email...
System and method for generating bilinear spatiotemporal basis models
Matthews, I.,
Akhter, I., Simon, T., Sohaib, K. and Sheikh, Y.
2013.
US Patent App. 13/425,369.
Abstract:
▸
Techniques are disclosed for generating a bilinear spatiotemporal basis model. A method includes the steps of predefining a trajectory basis for the bilinear spatiotemporal basis model, receiving three-dimensional spatiotemporal data for a training sequence, estimating a shape basis for the bilinear spatiotemporal basis model using the three-dimensional spatiotemporal data, and computing coefficients for the bilinear spatiotemporal basis model using the trajectory basis and the shape basis.
[Share]
Sending email...

A Study of X-Ray Image Perception for Pneumoconiosis Detection
MastersThesis: A Master's thesis.
IIIT-Hyderabad,
Hyderabad, India,
January
2013.
Abstract:
▸
Pneumoconiosis is an occupational lung disease caused by the inhalation of industrial dust. Despite the increasing safety measures and better work place environments, pneumoconiosis is deemed to be the most common occupational disease in the developing countries like India and China. Screening and assessment of this disease is done through radiological observation of chest x-rays. Several studies have shown the significant inter and intra reader observer variation in the diagnosis of this disease, showing the complexity of the task and importance of the expertise in diagnosis.
The present study is aimed at understanding the perceptual and cognitive factors affecting the reading of chest x-rays of pneumoconiosis patients. Understanding these factors helps in developing better image acquisition systems, better training regimen for radiologists and development of better computer aided diagnostic (CAD) systems. We used an eye tracking experiment to study the various factors affecting the assessment of this diffused lung disease. Specifically, we aimed at understanding the role of expertize, contralateral symmetric (CS) information present in chest x-rays on the diagnosis and the eye movements of the observers. We also studied the inter and intra observer fixation consistency along with the role of anatomical and bottom up saliency features in attracting the gaze of observers of different expertize levels, to get better insights into the effect of bottom up and top down visual saliency on the eye movements of observers.
The experiment is conducted in a room dedicated to eye tracking experiments. Participants consisting of novices (3), medical students (12), residents (4) and staff radiologists (4) were presented with good quality PA chest X-rays, and were asked to give profusion ratings for each of the 6 lung zones. Image set consisting of 17 normal full chest x-rays and 16 single lung images are shown to the participants in random order. Time of the diagnosis and the eye movements are also recorded using a remote head free eye tracker.
Results indicated that Expertise and CS play important roles in the diagnosis of pneumoconiosis. Novices and medical students are slow and inefficient whereas, residents and staff are quick and efficient. A key finding of our study is that the presence of CS information alone does not help improve diagnosis as much as learning how to use the information. This learning appears to be gained from focused training and years of experience. Hence, good training for radiologists and careful observation of each lung zone may improve the quality of diagnostic results. For residents, the eye scanning strategies play an important role in using the CS information present in chest radiographs; however, in staff radiologists, peripheral vision or higher-level cognitive processes seems to play role in using the CS information.
There is a reasonably good inter and intra observer fixation consistency suggesting the use of similar viewing strategies. Experience is helping the observers to develop new visual strategies based on the image content so that they can quickly and efficiently assess the disease level. First few fixations seem to be playing an important role in choosing the visual strategy, appropriate for the given image.
Both inter-rib and rib regions are given equal importance by the observers. Despite reading of chest x-rays being highly task dependent, bottom up saliency is shown to have played an important role in attracting the fixations of the observers. This role of bottom up saliency seems to be more in lower expertize groups compared to that of higher expertize groups. Both bottom up and top down influence of visual fixations seems to change with time. The relative role of top down and bottom up influences of visual attention is still not completely understood and it remains the part of future work.
Based on our experimental results, we have developed an extended saliency model by combining the bottom up saliency and the saliency of lung regions in a chest x-ray. This new saliency model performed significantly better than bottom-up saliency in predicting the gaze of the observers in our experiment. Even though, the model is a simple combination of bottom-up saliency maps and segmented lung masks, this demonstrates that even basic models using simple image features can predict the fixations of the observers to a good accuracy.
Experimental analysis suggested that the factors affecting the reading of chest x-rays of pneumoconiosis are complex and varied. A good understanding of these factors definitely helps in the development of better radiological screening of pneumoconiosis through improved training and also through the use of improved CAD tools. The presented work is an attempt to get insights into what these factors are and how they modify the behavior of the observers.
[Share]
Sending email...
Nonlinearly Constrained MRFs: Exploring the Intrinsic Dimensions of Higher-Order Cliques
Zeng, Y.,
Wang, C., Soatto, S. and Yau, S.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2013.
[Share]
Sending email...
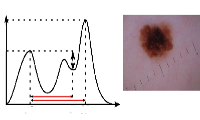
Simple, fast, accurate melanocytic lesion segmentation in 1D colour space
Peruch, F.,
Bogo, F., Bonazza, M., Bressan, M., Cappelleri, V. and Peserico, E.
In
VISAPP (1),
pages 191-200,
Barcelona.
February
2013.
[Share]
Sending email...
Simultaneous Cast Shadows, Illumination and Geometry Inference Using Hypergraphs
Panagopoulos, A.,
Wang, C., Samaras, D. and Paragios, N.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI),
35(2):437-449,
2013.
[Share]
Sending email...
Modeling Shapes with Higher-Order Graphs: Theory and Applications
Wang, C., Zeng, Y., Samaras, D. and Paragios, N.
In
Shape Perception in Human and Computer Vision: An Interdisciplinary Perspective,
Pizlo, Z. and Dickinson, S., Editors,
Springer,
2013.
[Share]
Sending email...

Image Gradient Based Level Set Methods in 2D and 3D
Xie, X.,
Yeo, S.Y., Mirmehdi, M., Sazonov, I. and Nithiarasu, P.
In
Deformation Models: Tracking, Animation and Applications,
Hidalgo, M.G., Torres, A.M. and Gómez, J.V., Editors,
Springer
pages 101-120,
2013.
Abstract:
▸
This chapter presents an image gradient based approach to perform 2D and 3D deformable model segmentation using level set. The 2D method uses an external force field that is based on magnetostatics and hypothesized magnetic interactions between the active contour and object boundaries. The major contribution of the method is that the interaction of its forces can greatly improve the active contour in capturing complex geometries and dealing with difficult initializations, weak edges and broken boundaries. This method is then generalized to 3D by reformulating its external force based on geometrical interactions between the relative geometries of the deformable model and the object boundary characterized by image gradient. The evolution of the deformable model is solved using the level set method so that topological changes are handled automatically. The relative geometrical configurations between the deformable model and the object boundaries contribute to a dynamic vector force field that changes accordingly as the deformable model evolves. The geometrically induced dynamic interaction force has been shown to greatly improve the deformable model performance in acquiring complex geometries and highly concave boundaries, and it gives the deformable model a high invariancy in initialization configurations. The voxel interactions across the whole image domain provide a global view of the object boundary representation, giving the external force a long attraction range. The bidirectionality of the external force field allows the new deformable model to deal with arbitrary cross-boundary initializations, and facilitates the handling of weak edges and broken boundaries.
[Share]
Sending email...

Regional comparison of left ventricle systolic wall stress reveals intraregional uniformity in healthy subjects
Teo, S.K.,
Yeo, S.Y., Tan, M.L., Lim, C.W., Zhong, L., Tan, R.S. and Su, Y.
In
Computing in Cardiology Conference,
pages 575 - 578,
2013.
Abstract:
▸
This study aimed to assess the feasibility of using the regional uniformity of the left ventricle (LV) wall stress (WS) to diagnose patients with myocardial infarction. We present a novel method using a similarity map that measures the degree of uniformity in nominal systolic WS across pairs of segments within the same patient. The values of the nominal WS are computed at each vertex point from a 1-to-1 corresponding mesh pair of the LV at the end-diastole (ED) and end-systole (ES) phases. The 3D geometries of the LV at ED and ES are reconstructed from border-delineated MRI images and the 1-to-1 mesh generated using a strain-energy minimization approach. The LV is then partitioned into 16 segments based on published clinical standard and the nominal WS histogram distribution for each of the segment was computed. A similarity index is then computed for each pair of histogram distributions to generate a 16-by-16 similarity map. Based on our initial study involving 12 MI patients and 9 controls, we observed uniformity for intra- regional comparisons in the controls compared against the patients. Our results suggest that the regional uniformity of the nominal systolic WS in the form of a similarity map can potentially be used as a discriminant between MI patients and normal controls.
[Share]
Sending email...
Reconstructing patient-specific cardiac models from contours via Delaunay triangulation and graph-cuts
Wan, M., Lim, C., Zhang, J., Su, Y.,
Yeo, S.Y., Wang, D., Tan, R.S. and Zhong, L.
In
International Conference of the IEEE Engineering in Medicine and Biology Society,
pages 2976-9,
2013.
[Share]
Sending email...
Puppet Flow
Technical Report
7,
Max Planck Institute for Intelligent Systems,
October
2013.
Abstract:
▸
We introduce Puppet Flow (PF), a layered model describing the optical flow of a person in a video sequence. We consider video frames composed by two layers: a foreground layer corresponding to a person, and background.
We model the background as an affine flow field. The foreground layer, being a moving person, requires reasoning about the articulated nature of the human body. We thus represent the foreground layer with the Deformable Structures model (DS), a parametrized 2D part-based human body representation. We call the motion field defined through articulated motion and deformation of the DS model, a Puppet Flow. By exploiting the DS representation, Puppet Flow is a parametrized optical flow field, where parameters are the person's pose, gender and body shape.
[Share]
Sending email...
System and method for simulating realistic clothing
Patent application PCT/US2013/026312,
February
2013.
Abstract:
▸
Systems, methods, and computer-readable storage media for simulating realistic clothing. The system generates a clothing deformation model for a clothing type, wherein the clothing deformation model factors a change of clothing shape due to rigid limb rotation, pose-independent body shape, and pose-dependent deformations. Next, the system generates a custom-shaped garment for a given body by mapping, via the clothing deformation model, body shape parameters to clothing shape parameters. The system then automatically dresses the given body with the custom- shaped garment.
[Share]
Sending email...

Branch&Rank for Efficient Object Detection
Lehmann, A.,
Gehler, P. and VanGool, L.
International Journal of Computer Vision,
2013.
Abstract:
▸
Ranking hypothesis sets is a powerful concept for efficient object detection. In this work, we propose a branch&rank scheme that detects objects with often less than 100 ranking operations. This efficiency enables the use of strong and also costly classifiers like non-linear SVMs with RBF-TeX kernels. We thereby relieve an inherent limitation of branch&bound methods as bounds are often not tight enough to be effective in practice. Our approach features three key components: a ranking function that operates on sets of hypotheses and a grouping of these into different tasks. Detection efficiency results from adaptively sub-dividing the object search space into decreasingly smaller sets. This is inherited from branch&bound, while the ranking function supersedes a tight bound which is often unavailable (except for rather limited function classes). The grouping makes the system effective: it separates image classification from object recognition, yet combines them in a single formulation, phrased as a structured SVM problem. A novel aspect of branch&rank is that a better ranking function is expected to decrease the number of classifier calls during detection. We use the VOC’07 dataset to demonstrate the algorithmic properties of branch&rank.
[Share]
Sending email...

Towards understanding action recognition
In
IEEE International Conference on Computer Vision (ICCV),
IEEE,
pages 3192-3199,
Sydney, Australia.
December
2013.
Abstract:
▸
Although action recognition in videos is widely studied, current methods often fail on real-world datasets. Many recent approaches improve accuracy and robustness to cope with challenging video sequences, but it is often unclear
what affects the results most. This paper attempts to provide insights based on a systematic performance evaluation
using thoroughly-annotated data of human actions. We annotate human Joints for the HMDB dataset (J-HMDB). This annotation can be used to derive ground truth optical flow and segmentation. We evaluate current methods using
this dataset and systematically replace the output of various algorithms with ground truth. This enables us to discover what is important – for example, should we work on improving flow algorithms, estimating human bounding boxes, or enabling pose estimation? In summary, we find that highlevel pose features greatly outperform low/mid level features; in particular, pose over time is critical, but current pose estimation algorithms are not yet reliable enough to provide this information. We also find that the accuracy of a top-performing action recognition framework can be greatly increased by refining the underlying low/mid level features; this suggests it is important to improve optical flow and human detection algorithms. Our analysis and JHMDB dataset should facilitate a deeper understanding of action recognition algorithms.
[Share]
Sending email...
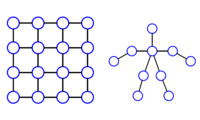
Markov Random Field Modeling, Inference & Learning in Computer Vision & Image Understanding: A Survey
Wang, C., Komodakis, N. and Paragios, N.
Computer Vision and Image Understanding (CVIU),
117(11):1610-1627,
November
2013.
Abstract:
▸
In this paper, we present a comprehensive survey of Markov Random Fields (MRFs) in computer vision and image understanding, with respect to the modeling, the inference and the learning. While MRFs were introduced into the computer vision field about two decades ago, they started to become a ubiquitous tool for solving visual perception problems around the turn of the millennium following the emergence of efficient inference methods. During the past decade, a variety of MRF models as well as inference and learning methods have been developed for addressing numerous low, mid and high-level vision problems. While most of the literature concerns pairwise MRFs, in recent years we have also witnessed significant progress in higher-order MRFs, which substantially enhances the expressiveness of graph-based models and expands the domain of solvable problems. This survey provides a compact and informative summary of the major literature in this research topic.
[Share]
Sending email...
A Generic Deformation Model for Dense Non-Rigid Surface Registration: a Higher-Order MRF-based Approach
Zeng, Y.,
Wang, C., Gu, X., Samaras, D. and Paragios, N.
In
IEEE International Conference on Computer Vision (ICCV),
pages 3360~3367,
2013.
[Share]
Sending email...
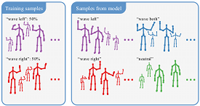
A Non-parametric Bayesian Network Prior of Human Pose
In
Proceedings IEEE Conf. on Computer Vision (ICCV),
pages 1281-1288,
December
2013.
Abstract:
▸
Having a sensible prior of human pose is a vital ingredient for many computer vision applications, including tracking and pose estimation. While the application of global non-parametric approaches and parametric models has led to some success, finding the right balance in terms of flexibility and tractability, as well as estimating model parameters from data has turned out to be challenging. In this work, we introduce a sparse Bayesian network model of human pose that is non-parametric with respect to the estimation of both its graph structure and its local distributions. We describe an efficient sampling scheme for our model and show its tractability for the computation of exact log-likelihoods. We empirically validate our approach on the Human 3.6M dataset and demonstrate superior performance to global models and parametric networks. We further illustrate our model's ability to represent and compose poses not present in the training set (compositionality) and describe a speed-accuracy trade-off that allows realtime scoring of poses.
[Share]
Sending email...

Strong Appearance and Expressive Spatial Models for Human Pose Estimation
Pishchulin, L., Andriluka, M.,
Gehler, P. and Schiele, B.
In
International Conference on Computer Vision (ICCV),
2013.
Abstract:
▸
Typical approaches to articulated pose estimation combine spatial modelling of the human body with appearance modelling of body parts. This paper aims to push the state-of-the-art in articulated pose estimation in two ways. First we explore various types of appearance representations aiming to substantially improve the body part hypotheses. And second, we draw on and combine several recently proposed powerful ideas such as more flexible spatial models as well as image-conditioned spatial models. In a series of experiments we draw several important conclusions: (1) we show that the proposed appearance representations are complementary; (2) we demonstrate that even a basic tree-structure spatial human body model achieves state-of-the-art performance when augmented with the proper appearance representation; and (3) we show that the combination of the best performing appearance model with a flexible image-conditioned spatial model achieves the best result, significantly improving over the state of the art, on the "Leeds Sports Poses'' and "Parse'' benchmarks.
[Share]
Sending email...

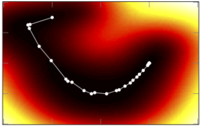
Estimating Human Pose with Flowing Puppets
In
IEEE International Conference on Computer Vision (ICCV),
pages 3312-3319,
2013.
Abstract:
▸
We address the problem of upper-body human pose estimation in uncontrolled monocular video sequences, without manual initialization. Most current methods focus on isolated video frames and often fail to correctly localize arms and hands. Inferring pose over a video sequence is advantageous because poses of people in adjacent frames exhibit properties of smooth variation due to the nature of human and camera motion. To exploit this, previous methods have used prior knowledge about distinctive actions or generic temporal priors combined with static image likelihoods to track people in motion. Here we take a different approach based on a simple observation: Information about how a person moves from frame to frame is present in the optical flow field. We develop an approach for tracking articulated motions that "links" articulated shape models of people in adjacent frames trough the dense optical flow. Key to this approach is a 2D shape model of the body that we use to compute how the body moves over time. The resulting "flowing puppets" provide a way of integrating image evidence across frames to improve pose inference. We apply our method on a challenging dataset of TV video sequences and show state-of-the-art performance.
[Share]
Sending email...
Metric Regression Forests for Human Pose Estimation
(Best Science Paper Award)
Pons-Moll, G., Taylor, J., Shotton, J., Hertzmann, A. and Fitzgibbon, A.
British Machine Vision Conference (BMVC) ,
BMVA Press,
September
2013.
[Share]
Sending email...
Understanding High-Level Semantics by Modeling Traffic Patterns
Zhang, H.,
Geiger, A. and Urtasun, R.
In
International Conference on Computer Vision,
pages 3056-3063,
Sydney, Australia.
December
2013.
Abstract:
▸
In this paper, we are interested in understanding the semantics of
outdoor scenes in the context of autonomous driving. Towards this
goal, we propose a generative model of 3D urban scenes which is able
to reason not only about the geometry and objects present in the
scene, but also about the high-level semantics in the form of traffic
patterns. We found that a small number of patterns is sufficient
to model the vast majority of traffic scenes and show how these patterns
can be learned. As evidenced by our experiments, this high-level
reasoning significantly improves the overall scene estimation as
well as the vehicle-to-lane association when compared to state-of-the-art
approaches. All data and code will be made available upon publication.
[Share]
Sending email...

Vision meets Robotics: The KITTI Dataset
Geiger, A., Lenz, P., Stiller, C. and Urtasun, R.
International Journal of Robotics Research,
32(11):1231 - 1237 ,
September
2013.
Abstract:
▸
We present a novel dataset captured from a VW station wagon for use in mobile robotics and autonomous driving research. In total, we recorded 6 hours of traffic scenarios at 10-100 Hz using a variety of sensor modalities such as high-resolution color and grayscale stereo cameras, a Velodyne 3D laser scanner and a high-precision GPS/IMU inertial navigation system. The scenarios are diverse, capturing real-world traffic situations and range from freeways over rural
areas to inner-city scenes with many static and dynamic objects. Our data is calibrated, synchronized and timestamped, and we provide the rectified and raw image sequences. Our dataset also contains object labels in the form of 3D tracklets and we provide online benchmarks for stereo, optical flow, object detection and other tasks. This paper describes our recording platform, the data format and the utilities that we provide.
[Share]
Sending email...

Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms
PhD thesis.
Karlsruhe Institute of Technology,
April
2013.
Abstract:
▸
Visual 3D scene understanding is an important component in autonomous
driving and robot navigation. Intelligent vehicles for example often
base their decisions on observations obtained from video cameras
as they are cheap and easy to employ. Inner-city intersections represent
an interesting but also very challenging scenario in this context:
The road layout may be very complex and observations are often noisy
or even missing due to heavy occlusions. While Highway navigation
and autonomous driving on simple and annotated intersections have
already been demonstrated successfully, understanding and navigating
general inner-city crossings with little prior knowledge remains
an unsolved problem. This thesis is a contribution to understanding
multi-object traffic scenes from video sequences. All data is provided
by a camera system which is mounted on top of the autonomous driving
platform AnnieWAY. The proposed probabilistic generative model reasons
jointly about the 3D scene layout as well as the 3D location and
orientation of objects in the scene. In particular, the scene topology,
geometry as well as traffic activities are inferred from short video
sequences. The model takes advantage of monocular information in
the form of vehicle tracklets, vanishing lines and semantic labels.
Additionally, the benefit of stereo features such as 3D scene flow
and occupancy grids is investigated. Motivated by the impressive
driving capabilities of humans, no further information such as GPS,
lidar, radar or map knowledge is required. Experiments conducted
on 113 representative intersection sequences show that the developed
approach successfully infers the correct layout in a variety of difficult
scenarios. To evaluate the importance of each feature cue, experiments
with different feature combinations are conducted. Additionally,
the proposed method is shown to improve object detection and object
orientation estimation performance.
[Share]
Sending email...