Export search results as:
BibTex
2012
Spatial Measures between Human Poses for Classification and Understanding
In
Articulated Motion and Deformable Objects,
Springer Berlin Heidelberg,
Vol. 7378,
LNCS,
pages 26-36,
2012.
[Share]
Sending email...

Local Context Priors for Object Proposal Generation
Ristin, M.,
Gall, J. and van Gool, L.
In
Asian Conference on Computer Vision (ACCV),
Springer-Verlag,
Vol. 7724,
LNCS,
pages 57-70,
2012.
[Share]
Sending email...

A naturalistic open source movie for optical flow evaluation
Butler, D.J.,
Wulff, J., Stanley, G.B. and
Black, M.J.
In
European Conf. on Computer Vision (ECCV),
Springer-Verlag,
Part IV, LNCS 7577,
pages 611-625,
October
2012.
Abstract:
▸
Ground truth optical flow is difficult to measure in real scenes with natural motion. As a result, optical flow data sets are restricted in terms of size, complexity, and diversity, making optical flow algorithms difficult to train and test on realistic data. We introduce a new optical flow data set derived from the open source 3D animated short film Sintel. This data set has important features not present in the popular Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, and atmospheric effects. Because the graphics data that generated the movie is open source, we are able to render scenes under conditions of varying complexity to evaluate where existing flow algorithms fail. We evaluate several recent optical flow algorithms and find that current highly-ranked methods on the Middlebury evaluation have difficulty with this more complex data set suggesting further research on optical flow estimation is needed. To validate the use of synthetic data, we compare the image- and flow-statistics of Sintel to those of real films and videos and show that they are similar. The data set, metrics, and evaluation website are publicly available.
[Share]
Sending email...
Lessons and insights from creating a synthetic optical flow benchmark
Wulff, J., Butler, D.J., Stanley, G.B. and
Black, M.J.
In
ECCV Workshop on Unsolved Problems in Optical Flow and Stereo Estimation,
Springer-Verlag,
Part II, LNCS 7584,
pages 168-177,
October
2012.
[Share]
Sending email...
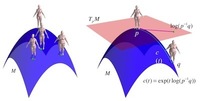
Lie Bodies: A Manifold Representation of 3D Human Shape
Freifeld, O. and
Black, M.J.
In
European Conf. on Computer Vision (ECCV),
Springer-Verlag,
Part I, LNCS 7572,
pages 1-14,
October
2012.
Abstract:
▸
Three-dimensional object shape is commonly represented in terms of deformations of a triangular mesh from an exemplar shape. Existing models, however, are based on a Euclidean representation of shape deformations. In contrast, we argue that shape has a manifold structure: For example, summing the shape deformations for two people does not necessarily yield a deformation corresponding to a valid human shape, nor does the Euclidean difference of these two deformations provide a meaningful measure of shape dissimilarity. Consequently, we define a
novel manifold for shape representation, with emphasis on body shapes, using a new Lie group of deformations. This has several advantages. First we define triangle deformations exactly, removing non-physical deformations
and redundant degrees of freedom common to previous methods. Second, the Riemannian structure of Lie Bodies enables a more meaningful definition of body shape similarity by measuring distance between bodies on the manifold of body shape deformations. Third, the group structure allows the valid composition of deformations. This is important for models that factor body shape deformations into multiple causes or represent shape as a linear combination of basis shapes. Finally, body shape variation is modeled using statistics on manifolds. Instead of modeling Euclidean shape variation with Principal Component Analysis we capture shape variation on the manifold using Principal Geodesic Analysis. Our experiments show consistent visual and quantitative advantages of Lie Bodies over traditional Euclidean models of shape deformation and our representation can be easily incorporated into existing methods.
[Share]
Sending email...
Destination Flow for Crowd Simulation
Pellegrini, S.,
Gall, J., Sigal, L. and van Gool, L.
In
Workshop on Analysis and Retrieval of Tracked Events and Motion in Imagery Streams,
Springer,
Vol. 7585,
LNCS,
pages 162-171,
2012.
[Share]
Sending email...
Consumer Depth Cameras for Computer Vision - Research Topics and Applications
Fossati, A.,
Gall, J., Grabner, H., Ren, X. and Konolige, K.
Advances in Computer Vision and Pattern Recognition,
Springer,
2012.
[Share]
Sending email...
Sparsity Potentials for Detecting Objects with the Hough Transform
Razavi, N., Alvar, N.,
Gall, J. and van Gool, L.
In
British Machine Vision Conference (BMVC),
BMVA Press,
pages 11.1-11.10,
2012.
[Share]
Sending email...
Metric Learning from Poses for Temporal Clustering of Human Motion
López-Méndez, A.,
Gall, J., Casas, J. and van Gool, L.
In
British Machine Vision Conference (BMVC),
BMVA Press,
pages 49.1-49.12,
2012.
[Share]
Sending email...
Motion Capture of Hands in Action using Discriminative Salient Points
Ballan, L., Taneja, A.,
Gall, J., van Gool, L. and Pollefeys, M.
In
European Conference on Computer Vision (ECCV),
Springer,
Vol. 7577,
LNCS,
pages 640-653,
2012.
[Share]
Sending email...
Latent Hough Transform for Object Detection
Razavi, N.,
Gall, J., Kohli, P. and van Gool, L.
In
European Conference on Computer Vision (ECCV),
Springer,
Vol. 7574,
LNCS,
pages 312-325,
2012.
[Share]
Sending email...
3D2PM – 3D Deformable Part Models
Pepik, B.,
Gehler, P., Stark, M. and Schiele, B.
In
Proceedings of the European Conference on Computer Vision (ECCV),
Springer,
Lecture Notes in Computer Science,
pages 356-370,
Firenze.
October
2012.
[Share]
Sending email...
Learning Search Based Inference for Object Detection
In
International Conference on Machine Learning (ICML) workshop on Inferning: Interactions between Inference and Learning,
Edinburgh, Scotland, UK.
July
2012.
short version of BMVC11 paper (http://ps.is.tue.mpg.de/publications/31/get_file).
[Share]
Sending email...
Pottics – The Potts Topic Model for Semantic Image Segmentation
Dann, C.,
Gehler, P., Roth, S. and Nowozin, S.
In
Proceedings of 34th DAGM Symposium,
Springer,
Lecture Notes in Computer Science,
pages 397-407,
August
2012.
[Share]
Sending email...
A framework for relating neural activity to freely moving behavior
Foster, J.D., Nuyujukian, P., Freifeld, O., Ryu, S.,
Black, M.J. and Shenoy, K.V.
In
34th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC’12),
IEEE,
pages 2736 -2739 ,
San Diego.
August
2012.
[Share]
Sending email...
Visual Orientation and Directional Selectivity Through Thalamic Synchrony
Stanley, G., Jin, J., Wang, Y., Desbordes, G., Wang, Q.,
Black, M. and Alonso, J.
Journal of Neuroscience,
32(26):9073-9088,
June
2012.
Abstract:
▸
Thalamic neurons respond to visual scenes by generating synchronous spike trains on the timescale of 10–20 ms that are very effective at driving cortical targets. Here we demonstrate that this synchronous activity contains unexpectedly rich information about fundamental properties of visual stimuli. We report that the occurrence of synchronous firing of cat thalamic cells with highly overlapping receptive fields is strongly sensitive to the orientation and the direction of motion of the visual stimulus. We show that this stimulus selectivity is robust, remaining relatively unchanged under different contrasts and temporal frequencies (stimulus velocities). A computational analysis based on an integrate-and-fire model of the direct thalamic input to a layer 4 cortical cell reveals a strong correlation between the degree of thalamic synchrony and the nonlinear relationship between cortical membrane potential and the resultant firing rate. Together, these findings suggest a novel population code in the synchronous firing of neurons in the early visual pathway that could serve as the substrate for establishing cortical representations of the visual scene.
[Share]
Sending email...

DRAPE: DRessing Any PErson
ACM Trans. on Graphics (Proc. SIGGRAPH),
31(4):35:1-35:10,
July
2012.
Abstract:
▸
We describe a complete system for animating realistic clothing on synthetic bodies of any shape and pose without manual intervention. The key component of the method is a model of clothing called DRAPE (DRessing Any PErson) that is learned from a physics-based simulation of clothing on bodies of different shapes and poses. The DRAPE model has the desirable property of "factoring" clothing deformations due to body shape from those due to pose variation. This factorization provides an approximation to the physical clothing deformation and greatly simplifies clothing synthesis. Given a parameterized model of the human body with known shape and pose parameters, we describe an algorithm that dresses the body with a garment that is customized to fit and possesses realistic wrinkles. DRAPE can be used to dress static bodies or animated sequences with a learned model of the cloth dynamics. Since the method is fully automated, it is appropriate for dressing large numbers of virtual characters of varying shape. The method is significantly more efficient than physical simulation.
[Share]
Sending email...
Coupled Action Recognition and Pose Estimation from Multiple Views
Yao, A.,
Gall, J. and van Gool, L.
International Journal of Computer Vision,
100(1):16-37,
October
2012.
[Share]
Sending email...
Real Time 3D Head Pose Estimation: Recent Achievements and Future Challenges
Fanelli, G.,
Gall, J. and van Gool, L.
In
5th International Symposium on Communications, Control and Signal Processing (ISCCSP),
2012.
[Share]
Sending email...
Data-driven Manifolds for Outdoor Motion Capture
In
Outdoor and Large-Scale Real-World Scene Analysis,
Dellaert, F., Frahm, J., Pollefeys, M., Rosenhahn, B. and Leal-Taixé, L., Editors,
volume 7474,
pages 305-328,
LNCS.
Springer,
2012.
[Share]
Sending email...
An Introduction to Random Forests for Multi-class Object Detection
Gall, J., Razavi, N. and van Gool, L.
In
Outdoor and Large-Scale Real-World Scene Analysis,
Dellaert, F., Frahm, J., Pollefeys, M., Rosenhahn, B. and Leal-Taixé, L., Editors,
volume 7474,
pages 243-263,
LNCS.
Springer,
2012.
[Share]
Sending email...
Interactive Object Detection
Yao, A.,
Gall, J., Leistner, C. and van Gool, L.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 3242-3249,
Providence, RI, USA.
2012.
[Share]
Sending email...
Real-time Facial Feature Detection using Conditional Regression Forests
Dantone, M.,
Gall, J., Fanelli, G. and van Gool, L.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 2578-2585,
Providence, RI, USA.
2012.
[Share]
Sending email...
Teaching 3D Geometry to Deformable Part Models
Pepik, B., Stark, M.,
Gehler, P. and Schiele, B.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 3362 -3369,
Providence, RI, USA.
2012.
oral presentation.
[Share]
Sending email...

Layered segmentation and optical flow estimation over time
Sun, D., Sudderth, E. and
Black, M.J.
In
IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 1768-1775,
2012.
Abstract:
▸
Layered models provide a compelling approach for estimating image motion and segmenting moving scenes. Previous methods, however, have failed to capture the structure of complex scenes, provide precise object boundaries, effectively estimate the number of layers in a scene, or robustly determine the depth order of the layers. Furthermore, previous methods have focused on optical flow between pairs of frames rather than longer sequences. We show that image sequences with more frames are needed to resolve ambiguities in depth ordering at occlusion boundaries; temporal layer constancy makes this feasible. Our generative model of image sequences is rich but difficult to optimize with traditional gradient descent methods. We propose a novel discrete approximation of the continuous objective in terms of a sequence of depth-ordered MRFs and extend graph-cut optimization methods with new “moves” that make joint layer segmentation and motion estimation feasible. Our optimizer,
which mixes discrete and continuous optimization, automatically determines the number of layers and reasons
about their depth ordering. We demonstrate the value of layered models, our optimization strategy, and the use of
more than two frames on both the Middlebury optical flow benchmark and the MIT layer segmentation benchmark.
[Share]
Sending email...
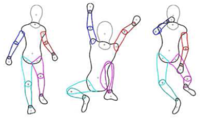
From pictorial structures to deformable structures
In
IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
IEEE,
pages 3546-3553,
June
2012.
Abstract:
▸
Pictorial Structures (PS) define a probabilistic model of 2D articulated objects in images. Typical PS models assume an object can be represented by a set of rigid parts connected with pairwise constraints that define the prior probability of part configurations. These models are widely used to represent non-rigid articulated objects such as humans and animals despite the fact that such objects have parts that deform non-rigidly. Here we define a new Deformable Structures (DS) model that is a natural extension of previous PS models and that captures the non-rigid shape deformation of the parts. Each part in a DS model is represented by a low-dimensional shape deformation space and pairwise potentials between parts capture how the shape varies with pose and the shape of neighboring parts. A key advantage of such a model is that it more accurately models object boundaries. This enables image likelihood models that are more discriminative than previous PS likelihoods. This likelihood is learned using training imagery annotated using a DS “puppet.” We focus on a human DS model learned from 2D projections of a realistic 3D human body model and use it to infer human poses in images using a form of non-parametric belief propagation.
[Share]
Sending email...
2011

Correspondence estimation from non-rigid motion information
Wulff, J., Lotz, T., Stehle, T., Aach, T. and Chase, J.G.
In
Proc. SPIE,
SPIE,
2011.
Abstract:
▸
The DIET (Digital Image Elasto Tomography) system is a novel approach to screen for breast cancer using only optical imaging information of the surface of a vibrating breast. 3D tracking of skin surface motion without the requirement of external markers is desirable. A novel approach to establish point correspondences using pure skin images is presented here. Instead of the intensity, motion is used as the primary feature, which can be extracted using optical flow algorithms. Taking sequences of multiple frames into account, this motion information alone is accurate and unambiguous enough to allow for a 3D reconstruction of the breast surface. Two approaches, direct and probabilistic, for this correspondence estimation are presented here, suitable for different levels of calibration information accuracy. Reconstructions show that the results obtained using these methods are comparable in accuracy to marker-based methods while considerably increasing resolution. The presented method has high potential in optical tissue deformation and motion sensing.
[Share]
Sending email...
Detecting synchrony in degraded audio-visual streams
Dhandhania, K.,
Wulff, J. and Sinha, P.
Journal of Vision,
11(11):800-800,
September
2011.
Abstract:
▸
Even 8–10 week old infants, when presented with two dynamic faces and a speech stream, look significantly longer at the ‘correct’ talking person (Patterson & Werker, 2003). This is true even though their reduced visual acuity prevents them from utilizing high spatial frequencies. Computational analyses in the field of audio/video synchrony and automatic speaker detection (e.g. Hershey & Movellan, 2000), in contrast, usually depend on high-resolution images. Therefore, the correlation mechanisms found in these computational studies are not directly applicable to the processes through which we learn to integrate the modalities of speech and vision. In this work, we investigated the correlation between speech signals and degraded video signals. We found a high correlation persisting even with high image degradation, resembling the low visual acuity of young infants. Additionally (in a fashion similar to Graf et al., 2002) we explored which parts of the face correlate with the audio in the degraded video sequences. Perfect synchrony and small offsets in the audio were used while finding the correlation, thereby detecting visual events preceding and following audio events. In order to achieve a sufficiently high temporal resolution, high-speed video sequences (500 frames per second) of talking people were used. This is a temporal resolution unachieved in previous studies and has allowed us to capture very subtle and short visual events. We believe that the results of this study might be interesting not only to vision researchers, but, by revealing subtle effects on a very fine timescale, also to people working in computer graphics and the generation and animation of artificial faces.
[Share]
Sending email...
A human inspired gaze estimation system
Journal of Vision,
11(11):507-507,
September
2011.
Abstract:
▸
Estimating another person's gaze is a crucial skill in human social interactions. The social component is most apparent in dyadic gaze situations, in which the looker seems to look into the eyes of the observer, thereby signaling interest or a turn to speak. In a triadic situation, on the other hand, the looker's gaze is averted from the observer and directed towards another, specific target. This is mostly interpreted as a cue for joint attention, creating awareness of a predator or another point of interest. In keeping with the task's social significance, humans are very proficient at gaze estimation. Our accuracy ranges from less than one degree for dyadic settings to approximately 2.5 degrees for triadic ones. Our goal in this work is to draw inspiration from human gaze estimation mechanisms in order to create an artificial system that can approach the former's accuracy levels. Since human performance is severely impaired by both image-based degradations (Ando, 2004) and a change of facial configurations (Jenkins & Langton, 2003), the underlying principles are believed to be based both on simple image cues such as contrast/brightness distribution and on more complex geometric processing to reconstruct the actual shape of the head. By incorporating both kinds of cues in our system's design, we are able to surpass the accuracy of existing eye-tracking systems, which rely exclusively on either image-based or geometry-based cues (Yamazoe et al., 2008). A side-benefit of this combined approach is that it allows for gaze estimation despite moderate view-point changes. This is important for settings where subjects, say young children or certain kinds of patients, might not be fully cooperative to allow a careful calibration. Our model and implementation of gaze estimation opens up new experimental questions about human mechanisms while also providing a useful tool for general calibration-free, non-intrusive remote eye-tracking.
[Share]
Sending email...

Multiview Structure from Motion in Trajectory Space
Zaheer, A.,
Akhter, I., Mohammad, H.B., Marzban, S. and Khan, S.
In
Computer Vision (ICCV), 2011 IEEE International Conference on,
IEEE,
pages 2447-2453,
2011.
Abstract:
▸
Most nonrigid objects exhibit temporal regularities in their deformations. Recently it was proposed that these regularities can be parameterized by assuming that the non- rigid structure lies in a small dimensional trajectory space. In this paper, we propose a factorization approach for 3D reconstruction from multiple static cameras under the com- pact trajectory subspace representation. Proposed factor- ization is analogous to rank-3 factorization of rigid struc- ture from motion problem, in transformed space. The benefit of our approach is that the 3D trajectory basis can be directly learned from the image observations. This also allows us to impute missing observations and denoise tracking errors without explicit estimation of the 3D structure. In contrast to standard triangulation based methods which require points to be visible in at least two cameras, our ap- proach can reconstruct points, which remain occluded even in all the cameras for quite a long time. This makes our solution especially suitable for occlusion handling in motion capture systems. We demonstrate robustness of our method on challenging real and synthetic scenarios.
[Share]
Sending email...

Trajectory Space: A Dual Representation for Nonrigid Structure from Motion
Akhter, I., Sheikh, Y., Khan, S. and Kanade, T.
Pattern Analysis and Machine Intelligence, IEEE Transactions on,
33(7):1442-1456,
July
2011.
Abstract:
▸
Existing approaches to nonrigid structure from motion assume that the instantaneous 3D shape of a deforming object is a linear combination of basis shapes. These basis are object dependent and therefore have to be estimated anew for each video sequence. In contrast, we propose a dual approach to describe the evolving 3D structure in trajectory space by a linear combination of basis trajectories. We describe the dual relationship between the two approaches, showing that they both have equal power for representing 3D structure. We further show that the temporal smoothness in 3D trajectories alone can be used for recovering nonrigid structure from a moving camera. The principal advantage of expressing deforming 3D structure in trajectory space is that we can define an object independent basis. This results in a significant reduction in unknowns, and corresponding stability in estimation. We propose the use of the Discrete Cosine Transform (DCT) as the object independent basis and empirically demonstrate that it approaches Principal Component Analysis (PCA) for natural motions. We report the performance of the proposed method, quantitatively using motion capture data, and qualitatively on several video sequences exhibiting nonrigid motions including piecewise rigid motion, partially nonrigid motion (such as a facial expressions), and highly nonrigid motion (such as a person walking or dancing).
[Share]
Sending email...

Role of expertise and contralateral symmetry in the diagnosis of pneumoconiosis: an experimental study
Jampani, V., Vaidya, V., Sivaswamy, J. and Tourani, K.L.
In
Proc. SPIE 7966, Medical Imaging: Image Perception, Observer Performance, and Technology Assessment,
Vol. 2011,
Florida.
March
2011.
Abstract:
▸
Pneumoconiosis, a lung disease caused by the inhalation of dust, is mainly diagnosed using chest radiographs. The effects of using contralateral symmetric (CS) information present in chest radiographs in the diagnosis of pneumoconiosis are studied using an eye tracking experimental study. The role of expertise and the influence of CS information on the performance of readers with different expertise level are also of interest. Experimental subjects ranging from novices & medical students to staff radiologists were presented with 17 double and 16 single lung images, and were asked to give profusion ratings for each lung zone. Eye movements and the time for their diagnosis were also recorded. Kruskal-Wallis test (χ2(6) = 13.38, p = .038), showed that the observer error (average sum of absolute differences) in double lung images differed significantly across the different expertise categories when considering all the participants. Wilcoxon-signed rank test indicated that the observer error was significantly higher for single-lung images (Z = 3.13, p < .001) than for the double-lung images for all the participants. Mann-Whitney test (U = 28, p = .038) showed that the differential error between single and double lung images is significantly higher in doctors [staff & residents] than in non-doctors [others]. Thus, Expertise & CS information plays a significant role in the diagnosis of pneumoconiosis. CS information helps in diagnosing pneumoconiosis by reducing the general tendency of giving less profusion ratings. Training and experience appear to play important roles in learning to use the CS information present in the chest radiographs.
[Share]
Sending email...
Intrinsic Dense 3D Surface Tracking
Zeng, Y.,
Wang, C.,
Wang, Y., Gu, X., Samaras, D. and Paragios, N.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2011.
[Share]
Sending email...
Tagged Cardiac MR Image Segmentation Using Boundary & Regional-Support and Graph-based Deformable Priors
Xiang, B.,
Wang, C., Deux, J., Rahmouni, A. and Paragios, N.
In
IEEE International Symposium on Biomedical Imaging (ISBI),
2011.
[Share]
Sending email...
Viewpoint Invariant 3D Landmark Model Inference from Monocular 2D Images Using Higher-Order Priors
Wang, C., Zeng, Y., Simon, L., Kakadiaris, I., Samaras, D. and Paragios, N.
In
IEEE International Conference on Computer Vision (ICCV),
2011.
[Share]
Sending email...

Geometrically Induced Force Interaction for Three-Dimensional Deformable Models
Yeo, S.Y., Xie, X., Sazonov, I. and Nithiarasu, P.
IEEE Transactions on Image Processing,
20(5):1373 - 1387,
2011.
Abstract:
▸
In this paper, we propose a novel 3-D deformable model that is based upon a geometrically induced external force field which can be conveniently generalized to arbitrary dimensions. This external force field is based upon hypothesized interactions between the relative geometries of the deformable model and the object boundary characterized by image gradient. The evolution of the deformable model is solved using the level set method so that topological changes are handled automatically. The relative geometrical configurations between the deformable model and the object boundaries contribute to a dynamic vector force field that changes accordingly as the deformable model evolves. The geometrically induced dynamic interaction force has been shown to greatly improve the deformable model performance in acquiring complex geometries and highly concave boundaries, and it gives the deformable model a high invariancy in initialization configurations. The voxel interactions across the whole image domain provide a global view of the object boundary representation, giving the external force a long attraction range. The bidirectionality of the external force field allows the new deformable model to deal with arbitrary cross-boundary initializations, and facilitates the handling of weak edges and broken boundaries. In addition, we show that by enhancing the geometrical interaction field with a nonlocal edge-preserving algorithm, the new deformable model can effectively overcome image noise. We provide a comparative study on the segmentation of various geometries with different topologies from both synthetic and real images, and show that the proposed method achieves significant improvements against existing image gradient techniques.
[Share]
Sending email...
Discrete Minimum Distortion Correspondence Problems for Non-rigid Shape Matching
Wang, C., Bronstein, M.M., Bronstein, A.M. and Paragios, N.
In
International Conference on Scale Space and Variational Methods in Computer Vision (SSVM),
2011.
[Share]
Sending email...
Pose-invariant 3D Proximal Femur Estimation through Bi-Planar Image Segmentation with Hierarchical Higher-Order Graph-based Priors
Wang, C., Boussaid, H., Simon, L., Lazennec, J. and Paragios, N.
In
International Conference, Medical Image Computing and Computer Assisted Intervention (MICCAI),
2011.
[Share]
Sending email...

Modelling pipeline for subject-specific arterial blood flow—A review
Sazonov, I.,
Yeo, S.Y., Bevan, R., Xie, X., van Loon, R. and Nithiarasu, P.
International Journal for Numerical Methods in Biomedical Engineering,
27(12):1868–1910,
2011.
Abstract:
▸
In this paper, a robust and semi-automatic modelling pipeline for blood flow through subject-specific arterial geometries is presented. The framework developed consists of image segmentation, domain discretization (meshing) and fluid dynamics. All the three subtopics of the pipeline are explained using an example of flow through a severely stenosed human carotid artery. In the Introduction, the state-of-the-art of both image segmentation and meshing is presented in some detail, and wherever possible the advantages and disadvantages of the existing methods are analysed. Followed by this, the deformable model used for image segmentation is presented. This model is based upon a geometrical potential force (GPF), which is a function of the image. Both the GPF calculation and level set determination are explained. Following the image segmentation method, a semi-automatic meshing method used in the present study is explained in full detail. All the relevant techniques required to generate a valid domain discretization are presented. These techniques include generating a valid surface mesh, skeletonization, mesh cropping, boundary layer mesh construction and various mesh cosmetic methods that are essential for generating a high-quality domain discretization. After presenting the mesh generation procedure, how to generate flow boundary conditions for both the inlets and outlets of a geometry is explained in detail. This is followed by a brief note on the flow solver, before studying the blood flow through the carotid artery with a severe stenosis.
[Share]
Sending email...

Computational flow studies in a subject-specific human upper airway using a one-equation turbulence model. Influence of the nasal cavity
Saksono, P., Nithiarasu, P., Sazonov, I. and
Yeo, S.Y.
International Journal for Numerical Methods in Biomedical Engineering,
87(1-5):96–114,
2011.
Abstract:
▸
This paper focuses on the impact of including nasal cavity on airflow through a human upper respiratory tract. A computational study is carried out on a realistic geometry, reconstructed from CT scans of a subject. The geometry includes nasal cavity, pharynx, larynx, trachea and two generations of airway bifurcations below trachea. The unstructured mesh generation procedure is discussed in some length due to the complex nature of the nasal cavity structure and poor scan resolution normally available from hospitals. The fluid dynamic studies have been carried out on the geometry with and without the inclusion of the nasal cavity. The characteristic-based split scheme along with the one-equation Spalart–Allmaras turbulence model is used in its explicit form to obtain flow solutions at steady state. Results reveal that the exclusion of nasal cavity significantly influences the resulting solution. In particular, the location of recirculating flow in the trachea is dramatically different when the truncated geometry is used. In addition, we also address the differences in the solution due to imposed, equally distributed and proportionally distributed flow rates at inlets (both nares). The results show that the differences in flow pattern between the two inlet conditions are not confined to the nasal cavity and nasopharyngeal region, but they propagate down to the trachea.
[Share]
Sending email...
Illumination Estimation and Cast Shadow Detection through a Higher-order Graphical Model
Panagopoulos, A.,
Wang, C., Samaras, D. and Paragios, N.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2011.
[Share]
Sending email...
High-quality reflection separation using polarized images
Kong, N., Tai, Y. and Shin, S.Y.
IEEE Transactions on Image Processing,
20(12):3393-3405,
December
2011.
Abstract:
▸
In this paper, we deal with a problem of separating the effect of reflection from images captured behind glass. The input consists of multiple polarized images captured from the same view point but with different polarizer angles. The output is the high quality separation of the reflection layer and the background layer from the images. We formulate this problem as a constrained optimization problem and propose a framework that allows us to fully exploit the mutually exclusive image information in our input data. We test our approach on various images and demonstrate that our approach can generate good reflection separation results.
[Share]
Sending email...
Extracting 3D Structures from Biomedical Data
Xie, X.,
Yeo, S.Y., Sazonov, I. and Nithiarasu, P.
Proceedings of the 5th International Conference on Bioinformatics and Biomedical Engineering,
2011.
[Share]
Sending email...
Variational Level Set Segmentation Using Shape Prior
Yeo, S.Y., Xie, X., Sazonov, I. and Nithiarasu, P.
In
International Conference on Mathematical and Computational Biomedical Engineering,
2011.
[Share]
Sending email...
Level Set Segmentation with Robust Image Gradient Energy and Statistical Shape Prior
Yeo, S.Y., Xie, X., Sazonov, I. and Nithiarasu, P.
In
IEEE International Conference on Image Processing,
pages 3397 - 3400,
2011.
Abstract:
▸
We propose a new level set segmentation method with statistical shape prior using a variational approach. The image energy is derived from a robust image gradient feature. This gives the active contour a global representation of the geometric configuration, making it more robust to image noise, weak edges and initial configurations. Statistical shape information is incorporated using nonparametric shape density distribution, which allows the model to handle relatively large shape variations. Comparative examples using both synthetic and real images show the robustness and efficiency of the proposed method.
[Share]
Sending email...
Model-Based Pose Estimation
In
Visual Analysis of Humans: Looking at People,
, Editors,
Springer
chapter 9
pages 139-170,
2011.
[Share]
Sending email...
Efficient and Robust Shape Matching for Model Based Human Motion Capture
Pons-Moll, G., Leal-Taixé, L., Truong, T. and Rosenhahn, B.
In
German Conference on Pattern Recognition (GCPR),
pages 416-425,
September
2011.
[Share]
Sending email...
Everybody needs somebody: modeling social and grouping behavior on a linear programming multiple people tracker
In
IEEE International Conference on Computer Vision Workshops (IICCVW),
November
2011.
[Share]
Sending email...
Outdoor Human Motion Capture using Inverse Kinematics and von Mises-Fisher Sampling
Pons-Moll, G., Baak, A., Gall, J., Leal-Taixe, L., Mueller, M., Seidel, H. and Rosenhahn, B.
In
IEEE International Conference on Computer Vision (ICCV),
pages 1243-1250,
November
2011.
[Share]
Sending email...
Adaptation for perception of the human body: Investigations of transfer across viewpoint and pose
Sekunova, A., Black, M.J., Parkinson, L. and Barton, J.S.
Vision Sciences Society,
2011.
[Share]
Sending email...