

From top-left to bottom-right: The input image with inferred segmentation into moving object hypotheses, the optical flow produced by our method, the disparity and optical flow ground truth of our novel scene flow dataset.
We propose a novel model and dataset for 3D scene flow estimation with an application to autonomous driving. Taking advantage of the fact that outdoor scenes often decompose into a small number of independently moving objects, we represent each element in the scene by its rigid motion parameters and each superpixel by a 3D plane as well as an index to the corresponding object. This minimal representation increases robustness and leads to a discrete-continuous CRF where the data term decomposes into pairwise potentials between superpixels and objects. Moreover, our model intrinsically segments the scene into its constituting dynamic components. We demonstrate the performance of our model on existing benchmarks as well as a novel realistic dataset with scene flow ground truth. We obtain this dataset by annotating 400 dynamic scenes from the KITTI raw data collection using detailed 3D CAD models for all vehicles in motion. Our experiments also reveal novel challenges which cannot be handled by existing methods.

We focus on the classical scene flow setting where the input is given by two consecutive stereo image pairs of a calibrated camera and the task is to determine the 3D location and 3D flow of each pixel in a reference frame.
Following the idea of piecewise-rigid shape and motion (Vogel et al. 2013), a slanted-plane model is used, i.e., we assume that the 3D structure of the scene can be approximated by a set of piecewise planar superpixels. As opposed to existing works, we assume a finite number of ridigly moving objects in the scene. Our goal is to recover this decomposition jointly with the shape of the superpixels and the motion of the objects. We specify the problem in terms of a discrete-continuous CRF
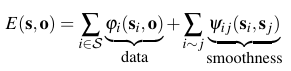
where s determines the shape and associated object of a superpixel, and o are the rigid motion parameters of all objects in the scene.
Currently there exists no realistic benchmark dataset providing dynamic objects and ground truth for the evaluation of scene flow or optical flow. Therefore, in this work, we take advantage of the KITTI raw data (Geiger et al. 2013) to create a realistic and challenging scene flow benchmark with independently moving objects and annotated ground truth, comprising 200 training and 200 test scenes in total. The process of ground truth generation is especially challenging in the presence of individually moving objects since they cannot be easily recovered from laser scanner data alone due to the rolling shutter of the Velodyne and the low framerate (10 fps). Our annotation work-flow consists of two major steps: First, we recover the static background of the scene by removing all dynamic objects and compensating for the vehicle's egomotion. Second, we re-insert the dynamic objects by fitting detailed CAD models to the point clouds in each frame. We make our dataset and evaluation available as part of the KITTI benchmark.
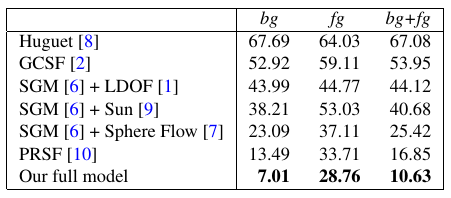
As input to our method, we leverage sparse optical flow from feature matches (Geiger et al. 2011) and SGM disparity maps (Hirschmüller 2008) for both rectified frames. We obtain superpixels using StereoSLIC (Yamaguchi et al. 2013) and initialize the rigid motion parameters of all objects in the scene by greedily extracting rigid body motion hypotheses using 3-point RANSAC. By reasoning jointly about the decomposition of the scene into its constituent objects as well as the geometry and motion of all objects in the scene, the proposed model is able to produce accurate dense 3D scene flow estimates, comparing favorably with respect to current state-of-the-art as illustrated in the table below. Our method also performs on par with the leading entries on the original static KITTI dataset (Geiger et al. 2012) as well as on the Sphere sequence of (Huguet et al. 2007).
Below, we show some of our qualitative results on the proposed dataset. Each subfigure shows from top-to-bottom: disparity and optical flow ground truth in the reference view, the disparity map (D1) and optical flow map (Fl) estimated by our algorithm, and the respective error images using the color scheme described in the paper (blue = correct estimates, red = wrong estimates). The last two scenes are failure cases of our method due to extreme motions or difficult illumination conditions.







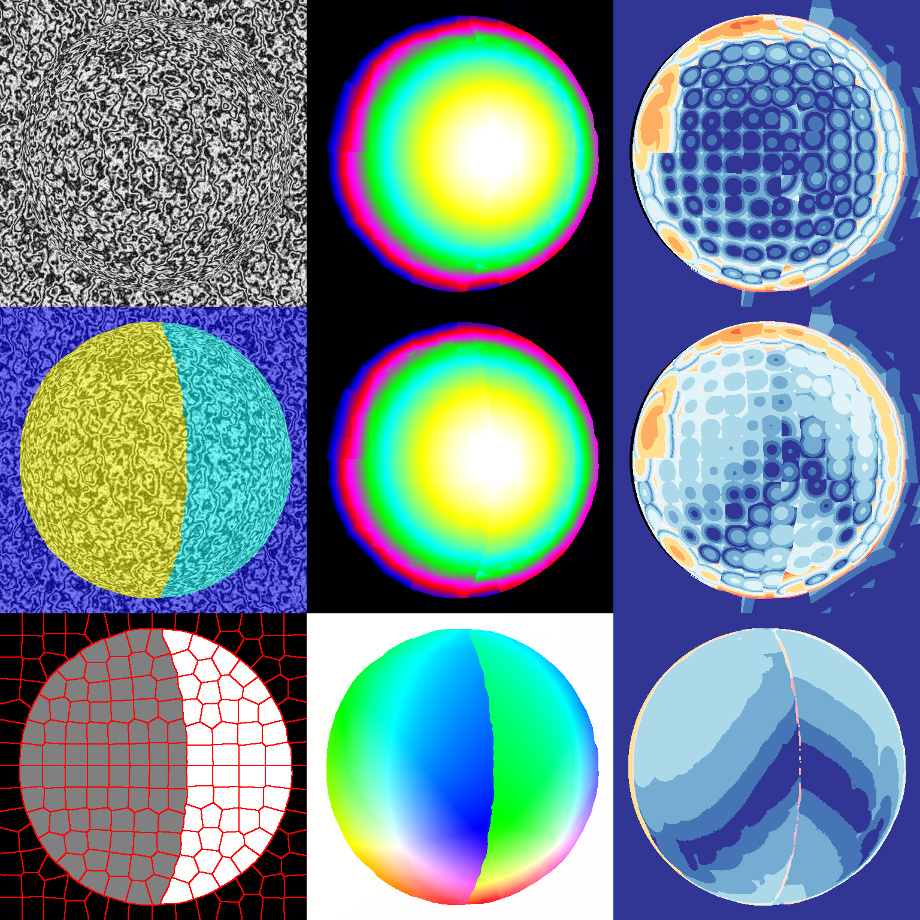
Below, we show results of our method on the Sphere dataset (Huguet et al. 2007). Due to the fundamental different properties of this dataset, we have chosen a different parameter setting and based the calculation of the superpixels on optical flow instead of intensities. Each subfigure shows from top-left to bottom-right: The input image, the estimated disparity map in the first frame, the respective disparity error, the estimated segmentation into different flow components, the estimated disparity map in the second frame, the respective disparity error, the superpixelization obtained from optical flow, the estimated optical flow, and the optical flow error.
The video below illustrates our results on a video sequence in terms of the disparity (top) and optical flow (bottom) estimated for the reference frame. Best viewed using YouTube's HD 720 setting.
The source code for this project has been tested on Ubuntu 14.04 and Matlab 2013b and is published under the GNU General Public License.
- Paper (pdf, 6 MB)
- Extended Abstract (pdf, 1 MB)
- Supplementary Material (pdf, 26 MB)
- Code (Matlab/C++, available summer 2015)
- Dataset (Stereo 2015 / Optical Flow 2015 / SceneFlow 2015, available summer 2015)

