
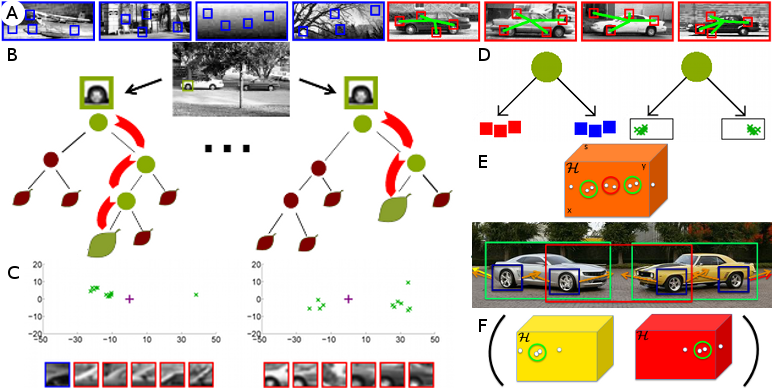
A. For training, a subset of image patches is taken from the entire training set. In the simplest case, there are only two classes; one containing negative or background examples (blue) and another containing positive examples (red). While the class labels are required to distinguish object patches from background patches (classification), additional offset vectors of the positive patches to the center of the object are stored (green). The offset vectors will be used to predict the location of the object (regression). B. A random forest consists of a set of trees that map an image patch to a distribution stored at each leaf. The spheres indicate split nodes that evaluate the appearance of a patch and pass it to the right or left child until a leaf is reached. C. Visualization of some leaves of a tree for detecting cars. Each leaf node stores the probability of a patch belonging to the object class, estimated by the proportion of patches from the positive (red) and negative examples (blue) reaching the leaf during training. For the positive class, the offset vectors are shown (green). The positive training examples falling inside each of the leaves can be associated with different parts of a car. D. Each split node separates the training data. The split nodes are optimized according to a classification objective that separates patches with different class labels and a regression objective that maximizes the localization accuracy of the offsets. E. During detection, image patches are passed through the trees and cast weighted votes to a Hough space (orange) where objects are detected by localizing the modes in the Hough space. Due to the independence of the patches, false detections (red) can occur. F. False detections can be reduced by enforcing consistency among votes using latent Hough spaces.
Object detection for real world applications is still a challenging problem. While recent research datasets increase the amount of training and testing examples to get closer to real world problems, the ability of detectors to process large data sets in reasonable time becomes another important issue besides accuracy. It is not only the number of training examples that matters, but also the number of classes.
A family of methods that can handle large amount of training data efficiently and that are inherently suited for multi-class problems are based on random forests. Random forests are ensembles of randomized decision trees that can be applied for regression, classification tasks, and even both at the same time.
A random forest consist of a set of trees where each tree consists of split nodes and leaves. The split nodes evaluate each arriving image patch and, depending on the appearance of the patch, pass it to the left or right child. Each leaf stores the statistics of the image patches that arrived during training. For a classification task, it is the probability for each class. For a regression task, it is a distribution over the continuous parameter that one wants to estimate. While image segmentation is a typical classification task where one wants to estimate the class label for each image patch, object localization can be regarded as a regression problem where each patch of the object predicts the location of the object in the image. Since object detection involves both classifying patches belonging to an object and using them to regress the location and scale of the object, random forests for object detection need to be trained to satisfy both objectives.
For training, a set of images is collected where each object is annotated by a bounding box and the class label. The background images are only annotated by the class label. In order to handle a large amount of training data and to avoid over fitting, randomness is introduced by training each tree on a randomly sampled subset of the training data. For object detection, this means to select a random set of images for each class and to sample a subset of patches for each image. For each sampled patch that does not belong to the background, the offset to a reference point of the object is stored. In order to train a tree that can be used for object detection, split functions for each non-leaf node are selected that separate the training patches in an optimal way. This is achieved by selecting split functions that maximize the gain of the classification or regression performance of the children in comparison to the current node.
For detecting an object, image patches are sampled from a test image and passed through the trees. The image patches can be densely sampled or sub-sampled as for training. Each patch ends in a leaf for each tree. In order to locate an object in the image, the probability of an object hypothesis is evaluated, i.e., the probability of an object of certain scale and image location. Besides of scale, additional parameters of the object like depth, viewpoint, or aspect ratio can be estimated.
Having introduced the concept of Hough forests, also termed classification-regression forests, for object detection, our research is focused on investigating all relevant aspects of Hough forests. For instance, two recent developments have been the latent Hough transform and an interactive annotation tool:
While Hough transform based object detection allows parts observed in different training instances to support a single object hypothesis, it also produces false positives by accumulating votes that are consistent in location but inconsistent in other properties like pose, color, shape or type. To address this problem, the Hough transform can be augmented with latent variables in order to enforce consistency among votes. To this end, only votes that agree on the assignment of the latent variable are allowed to support a single hypothesis. For training a latent Hough transform model, the linearity of Hough transform based methods can be exploited.
Based on the Hough forest framework, we have developed an interactive object annotation method that incrementally trains an object detector while the user provides annotations. In the design of the system, we have focused on minimizing human annotation time rather than pure algorithm learning performance. To this end, we optimize the detector based on a realistic annotation cost model based on a user study. Since our system gives live feedback to the user by detecting objects on the fly and predicts the potential annotation costs of unseen images, data can be efficiently annotated by a single user without excessive waiting time. In contrast to popular tracking-based methods for video annotation, the method is suitable for both still images and video.
2
3 ETH Zurich






