
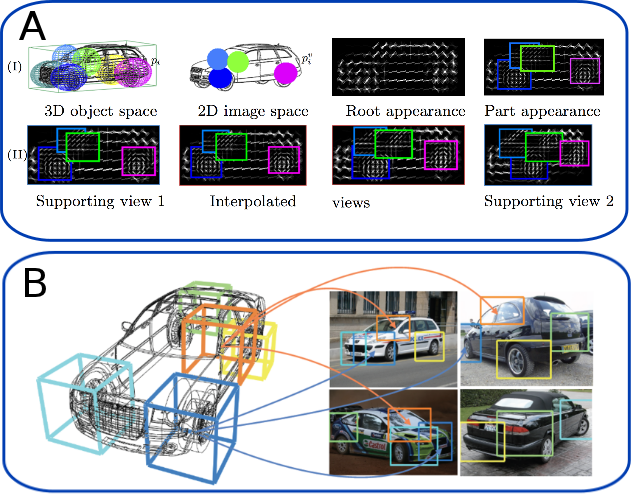
Our object detection model reasons about the objects in three dimensions. Therefore it can not only detect objects but also provide a continuous viewpoint estimate.
In the top figure we visualize the model of a car that includes part deformations in 3D (top left). For test time inference these are then projected into the 2D image plane (first row, second col). We also model appearance from any viewpoint on a circle around the object. Some examples filters can be seen in the black figures.
The bottom figure shows four different images of cars are along with the detection from our system. Note that the parts of the detections are in correspondance; e.g. the left rear part of the car (in yellow) is always at the corresponding place in the image although this part undergoes a severe appearance change.
In this project we address the problem of localizing and recognizing images of objects in real world cluttered environments. Real physical objects are inherently three dimensional, however for recognition in still images we have access only to 2D projections of them. This projection results in ambiguities of object appearance. Therefore the predominant paradigm today, is to largely ignore the 3D structure, and attack object class recognition using 2D feature based models.
In contrast to this, in this project we investigate models that take into account the 3D structure of objects. We believe that such richer output structure is needed especially to aid higher level tasks such as 3D scene understanding. For tasks like reasoning about free space in a scene, performing finer grained object categorization, and reasoning about geometry of scenes, a simple bounding box annotation will not be enough. However bounding box annotations are still encouraged by the standard object detection challenges such as the Pascal VOC. We would like to overcome this.
We believe that the desired output of an object detection model should include a viewpoint estimate along with a precise segmentation mask of where an object in the image is located along with how it is oriented. We address this in a first step by performing 3D bounding box detection in two dimensional images. We extend a state-of-the-art model, namely the Deformable Parts Model (DPM) from Felzenszwalb et al., to a full 3D object model. The DPM is a mixture of star based CRF models that include the deformation and appearance terms. We propose a CRF that models an object directly in 3D using 3D deformation and appearance terms that can be evaluated using any image projection. During inference we then reason about where an object is and what the transformation from 3D to 2D was. Knowing the projection our model reduces to a "standard" DPM and such allows to reuse the efficient inference techniques that have been developed lately.
Since most benchmark datasets only provide 2D views of object instances we have to tap another source to learn the 3D structure of objects. Therefore we investigate the use of CAD models. These may not provide photo realistic appearance but it turns out they can be used to teach the model about the 3D structure of objects. The benefit from using CAD data is that they can be rendered at any orientation and scale with full control over the output variables.
We evaluate the models both on standard 2D benchmark datasets as well as datasets that provide 3D information.
2 Stanford



