

Result of our method on a challenging image from the KITTI benchmark. The left figure shows the input image with the inferred object wireframe models overlayed. The right figure depicts the jointly inferred disparity map.
Stereo techniques have witnessed tremendous progress over the last decades, yet some aspects of the problem still remain challenging today. Striking examples are reflecting and textureless surfaces which cannot easily be recovered using traditional local regularizers. In this work, we therefore propose to regularize over larger distances using object-category specific disparity proposals (displets) which we sample using inverse graphics techniques based on a sparse disparity estimate and a semantic segmentation of the image. The proposed displets encode the fact that objects of certain categories are not arbitrarily shaped but typically exhibit regular structures. We integrate them as non-local regularizer for the challenging object class 'car' into a superpixel based CRF framework and demonstrate its benefits on the KITTI stereo evaluation. Our approach currently ranks first across all KITTI stereo leaderboards.

In this work, we investigate the utility of mid-level processes such as object recognition and semantic segmentation for the stereo matching task. In particular, we focus our attention on the reconstruction of well-defined objects for which the data term is weak and current methods perform poorly, such as cars. Due to their textureless, reflective and semi-transparent nature, those object categories represent a major challenge for current state-of-the-art algorithms. In contrast, as humans we are able to effortlessly extract information about the geometry of cars even from a single image thanks to our object knowledge and shape representation.
Inspired by this fact, we introduce object knowledge for well-constrained object categories into a slanted-plane MRF and estimate a dense disparity map. We leverage semantic information and inverse graphics to sample a set of plausible object disparity maps given an initial semi-dense disparity estimate. We encourage the presence of these 2.5D shape samples (displets) in our MRF formulation depending on how much their geometry and semantic class agrees with the observation. Intuitively, displets can be thought of as a representative finite subset of the infinitely large set of possible disparity maps for a certain semantic category conditioned on the image. For example, car displets should cover the most likely 3D car configurations and shapes given the two input images.
We assume that the image can be decomposed into a set of planar superpixels S and each superpixel is associated with a random variable n describing a plane in 3D. D denotes the set of displets in the image and each displet is associated with its class label c, a fitness value, and a set of superpixels on which it is defined. An additional random variable d, which can be interpreted as auxiliary variable in a high-order CRF, denotes the presence (d=1) or absence (d=0) of the displet in the scene. Furthermore, we assume that we have access to a rough semantic segmentation of the image. Our goal is to jointly infer all superpixel plane parameters as well as the presence or absence of all displets in the scene. We specify our CRF in terms of an energy function
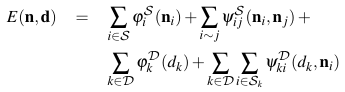
where i ~ j denotes the set of adjacent superpixels in S. In addition to the classic data term and pairwise constraints, we introduce long-range interactions into our model using displets: The displet unary potential (third term) encourages image regions with semantic class label c to be explained by a displet of the corresponding class. The last term ensures the displet and the associated superpixels in the image to be consistent.
Our experiments indicate that the proposed framework is able to resolve stereo ambiguities on challenging stereo pairs from the KITTI benchmark as illustrated in the figure at the top of this page. At the same time our method is able to extract 3D object representations which are consistent with the estimated disparity map and may serve as input to higher-level reasoning. The table shows quantitative results on the KITTI stereo benchmark at the time of submission using the default error threshold of 3 pixels in all regions (left) and reflective regions (right). The numbers represent outliers (in %) and average disparity errors (in pixels). Methods marked with an asterisk are scene flow methods which use two or more stereo image pairs as input.

Below, we show three qualitative results in terms of the inferred displets as well as the influence of the displets on the geometry of the superpixels. The influence is encoded as alpha channel: transparent = no influence, solid = large influence.
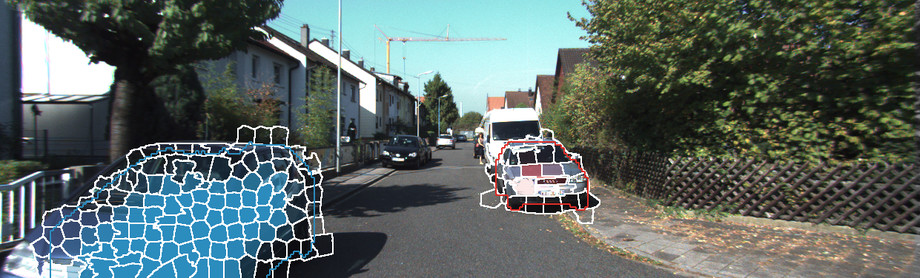
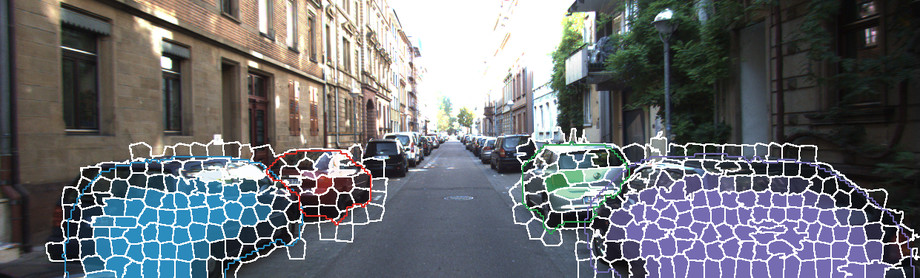

Below, we visualize our results in terms of inferred disparity maps on three different examples. Top-left: Input image, top-right: Semantic segments from ALE, bottom-left: input disparity map obtained via semi-global matching (SGM), bottom-right: our result.



The videos below illustrate our approach and results. For efficiency, we simplify the CAD models obtained from 3D Warehouse to 1000 faces by fitting a closed mesh initialized to the convex hull to a 3D CAD model using an energy minimization approach (yielding a 'semi-convex' hull). This process is illustrated in the left video and results in sampling rates of around 8000 fps on a standard consumer GPU (NVIDIA Quadro 4000). The right video illustrates the disparity maps produced by a state-of-the-art baseline (left) and our method (right) in terms of the respective colored 3D point cloud. Note how our approach is able to improve in particular on textureless, reflecting and semi-transparent surfaces.
The source code for this project has been tested on Ubuntu 14.04 and Matlab 2013b and is published under the GNU General Public License.
- Paper (pdf, 4 MB)
- Extended Abstract (pdf, 1 MB)
- Supplementary Material (pdf, 10 MB)
- Code (Matlab/C++)
- Data (Annotations/3D Models)
