
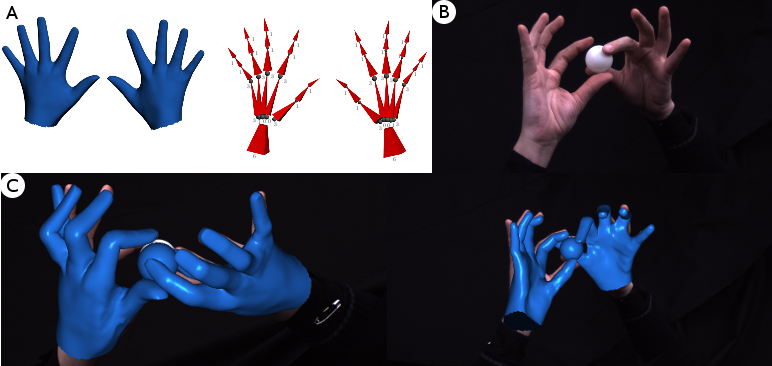
Capturing the motion of two hands interacting with an object. A. Mesh models (blue) and underlying bone skeletons (red) are used to represent the hands in the scene. B. One frame of a sequence where two hands are interacting with a ball. This sequence consists of a total of 73 degrees of freedom and has been captured by 8 synchronized cameras. C. Estimated poses of the hands and the ball superimposed on two different camera views.
Capturing the motion of hands is a very challenging computer vision problem that is also highly relevant for other areas like computer graphics, human-computer interfaces, or robotics. While intrusive methods like data gloves or color gloves provide an acceptable solution for some applications, marker-less hand tracking is still an unsolved problem.
Although the problem has been studied since the nineties, most approaches have focused on tracking a single hand in isolation. While this, in itself, is very challenging due to the many degrees of freedom, as well as due to self-occlusions and similarities between the fingers, we address the even more challenging problem of capturing the articulated motion of two hands that interact with each other and with an additional object.
To cope with the many degrees of freedom involved, multiple occlusions and appearance similarities between the hands and the fingers, we combine multiple visual features such as edges, optical flow, salient points, and collision constraints within an almost everywhere differentiable objective function for pose estimation. In this way, we can resort to simple local optimization techniques for pose estimation. To overcome the ambiguities of assigning salient points to the fingers of the two hands, we solve the salient point association and the pose estimation
problem simultaneously, to drastically improve the pose estimation accuracy.
For pose estimation, we present each trackable element in the scene as a linear blend skinned model consisting of a surface mesh model and an underlying bone skeleton. In this model, surface deformations are encoded using the linear blend skinning operator (LBS), which maps skeleton configurations into mesh vertex positions. Each hand consists of 20 bones and has 35 degrees of freedom (DOF).
The captured videos are assumed to be synchronized and spatially calibrated. The recording cameras are assumed to be static for the entire recording and the projection function, mapping 3D space points into image plane points, is assumed to be known for each camera. The recorded videos are first processed in order to extract important visual features like edges and optical flow. In the case of close interactions between hands, classical features like edges and optical flow, however, are insufficient to completely resolve for pose ambiguities. In fact, color edges completely disappear when hands touch each other since their color is very similar.
To cope with these ambiguities, we discriminatively learn the appearance of some characteristic features on the hands and detect them on each recorded video. In particular, we focus on finger nails because of their distinct appearance which is invariant to different hand poses. Since the appearance of nails across fingers is very similar, the association of detections and fingers is performed jointly during the pose estimation and included as an additional unknown to our problem.
In our experiments, we demonstrate that our approach can deal with very challenging sequences containing hands in action with and without an object and is also robust to errors in the salient point detector. In a quantitative comparison, we have shown that our proposed method with local optimization achieves a significantly lower hand pose error than a state-of-the-art hand tracking method based on an evolutionary algorithm.
Our current research is focused on relaxing the current assumptions of the system like the capturing with synchronized cameras in a studio environment or the acquisition of person specific hand models.
2
3 ETH Zurich





